Previous: Overview and Synopsis Up: Introduction and Background Next: Reconfigurable Computing Background
In this chapter we introduce much of the terminology used
throughout the document. We start with a high-level review of
general-purpose computing. We define the distinction between
programmable and configurable devices and the various components of
configurable devices. Much of the discussion will take Field-Programmable
Gate Arrays as a basis, so we introduce an initial, conceptual FPGA model.
Finally, we define metrics for capacity, density, and diversity which will
be used when characterizing the various architectures reviewed. A glossary
summarizing terminology follows Chapter .
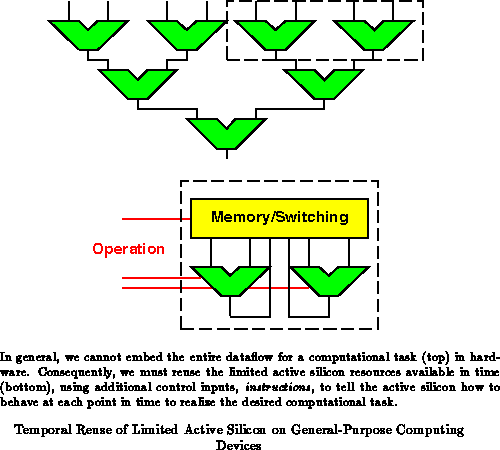
General-purpose computing devices are specifically intended for those cases where, economically, we cannot or need not dedicate sufficient spatial resources to support an entire computational task or where we do not know enough about the required task or tasks prior to fabrication to hardwire the functionality. The key ideas behind general-purpose processing are:
We are quite accustomed to exploiting these properties so that unique hardware is not required for every task or application. This basic theme recurs at many different levels in our conventional systems:
In the past, processors were virtually the only devices which had these characteristics and served as general-purpose building blocks. Today, many devices, including reconfigurable components, also exhibit the key properties and benefits associated with general-purpose computing. These devices are economically interesting for all of the above reasons.
There are two key features associated with general-purpose computers which distinguish them from their specialized counterparts. The way these aspects are handled plays a large role in distinguishing various general-purpose computing architectures.
In general-purpose machines, the datapaths between functional units cannot be hardwired. Different tasks will require different patterns of interconnect between the functional units. Within a task individual routines and operations may require different interconnectivity of functional units. General-purpose machines must provide the ability to direct data flow between units. In the extreme of a single functional unit, memory locations are used to perform this routing function. As more functional units operate together on a task, spatial switching is required to move data among functional units and memory. The flexibility and granularity of this interconnect is one of the big factors determining yielded capacity on a given application.
The distinction between programmable devices and
configurable devices is mostly artificial -- particularly
since we show in Part that these architectures can be viewed in
one unified design space. Nonetheless, it is useful to distinguish the
extremes due to their widely varying characteristics.
Programmable -- we will use the term ``programmable'' to refer to architectures which heavily and rapidly reuse a single piece of active circuitry for many different functions. The canonical example of a programmable device is a processor which may perform a different instruction on its ALU on every cycle. All processors, be they microcoded, SIMD, Vector, or VLIW are included in this category.
Configurable -- we use the term ``configurable'' to refer to architectures where the active circuitry can perform any of a number of different operations, but the function cannot be changed from cycle to cycle. FPGAs are our canonical example of a configurable device. Once the instruction has been ``configured'' into the device, it is not changed during an operational epoch.
One of the key distinction, then, is the balance between a piece of (1) active logic and its associated interconnect, and (2) the local memory to configure the operation of the logic and interconnect. We define one configuration context as the collection of bits which describe the behavior of a general-purpose machine on one operation cycle. One programming stream for a conventional FPGA containing instructions for every array element along with interconnect composes a ``configuration context.'' One might also think of each of the following as a configuration context.
A Field-Programmable Gate Array (FPGA) is a collection of
configurable processing units embedded in a configurable interconnection
network. In the context of general-purpose computing, we concern ourselves here
primarily with devices which can be reprogrammed.
Figure shows the basic model.
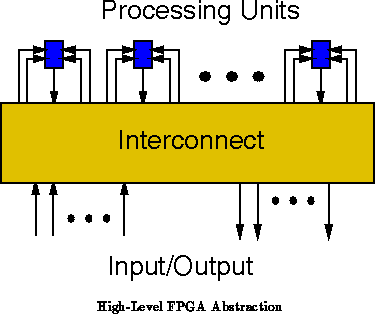
From the high-level view shown in Figure , the
FPGA looks much like a network of processors. A conventional FPGA,
however, differs from a conventional multiprocessor in several ways:
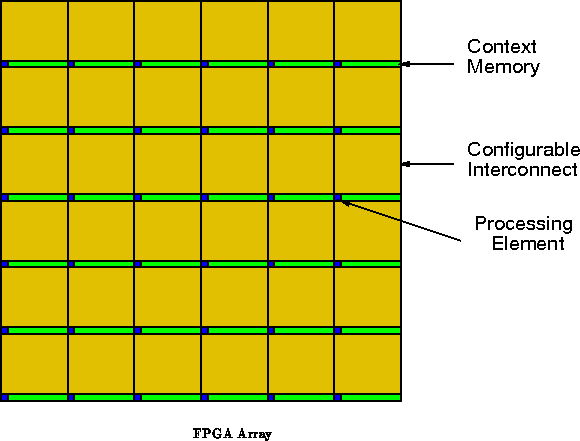
Processing elements are generally organized in an array on the IC
die with less than complete interconnect (See Figure ).
Since full connectivity would grow as
, FPGAs employ more
restricted connection schemes to limit the resources required for
interconnect which are, nonetheless, the dominant area component in
conventional devices. When processing elements are homogeneous, as is
typically the case, device placement can be used to improve interconnect
locality and accommodate the limited interconnect. The interconnect is
typically arranged in a hierarchical mesh.
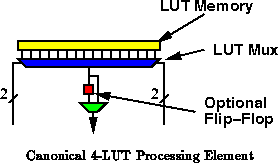
The processing elements, themselves, are simple functions combining a small number of inputs to produce a single output. The most general such function being a Look-Up Table (LUT). We have already noticed that the active logic function typically makes up only a small portion of the area. Further, it turns out that most of the configuration memory goes into describing the programmable interconnect. Consequently, for processing elements with a small number of inputs, the cost of using a full look-up table for the programmable logic function, versus some more restricted programmable element, is small.
We will use 4-input lookup tables (4-LUTs), as the canonical FPGA
processing element for the purpose of discussion and comparisons. To first
order, reconfigurable FPGAs from Xilinx [Xil94a][CDF +86],
Altera [Alt95], and AT&T [ATT95] use 4-LUTs as their basic,
constituent processing elements. Research at the University of Toronto
[RFLC90] indicates that four input LUTs yield the most
area efficient designs across a collection circuit benchmarks. An optional
flip-flop is generally associated with each 4-LUT. Figure
shows the canonical, 4-LUT processing element.
Throughout the thesis we make comparisons between processors and FPGAs. At times it is convenient to equate small LUTs (2 to 4-LUTs) and ALU bits. It is therefore, worthwhile to note that a 2-LUT can perform any logical operation including those provided by typical ALUs ( e.g. AND, OR, XOR, INVERT). A 3-LUT can act as a half-adder. A pair of 3-LUTs can serve as an adder or subtracter bit-slice with one bit providing the carry out the other the data bit output. Together these cover all the standard arithmetic and logic operations in a typical ALU, such that one or two 3-LUTs, with appropriate interconnect, can subsume any single ALU bit function.
Computing tasks can be classified informally by their regularity. Regular tasks perform the same sequence of operations repeatedly. Regular tasks have few data dependent conditionals such that all data processed requires essentially the same sequence of operations with highly predictable flow of execution. Nested loops with static bounds and minimal conditionals are the typical example of regular computational tasks. Irregular computing tasks, in contrast, perform highly data dependent operations. The operations required vary widely according to the data processed, and the flow of operation control is difficult to predict.
The goal of general-purpose computing devices is to provide a common, computational substrate which can be used to perform any particular task. In this section, we look at characterizing the amount of computation provided by a given general-purpose structure.
To perform a particular computational task, we must extract a certain amount of computational work from our computing device. If we were simply comparing tasks in terms of a fixed processor instruction set, we might measure this computational work in terms of instruction evaluations. If we were comparing tasks to be implemented in a gate-array we might compare the number of gates required to implement the task and the number of time units required to complete it. Here, we want to consider the portion of the computational work done for the task on each cycle of execution of diverse, general-purpose computing devices of a certain size. The ultimate goal is to roughly quantify the computational capacity per unit area provided to various application types by the computational organizations under consideration. That is, we are trying to answer the question:
``What is the general-purpose computing capacity provided by this computing structure.''
We have two immediate problems answering this questions:
The first question is difficult since it places little bounds on the properties of the computational tasks. We can, however, talk about the performance of computing structures in terms of some general properties which various important subclasses of general-purpose computing tasks exhibit. We thus end up addressing more focussed questions, but ones which give us insight into the properties and conditions under which various computational structures are favorable.
We will address the second question -- that of characterizing
device capacity -- using a ``gate-evaluation'' metric. That is, we
consider the minimum size circuit which would be required to implement a
task and count the number of gates which must be evaluated to realize the
computational task. We assume the collection of gates available are all
-input logic gates, and use
. This models our 4-LUT as discussed
in Section
, as well as more traditional gate-array logic.
The results would not change characteristically using a different, finite
value as long as
.
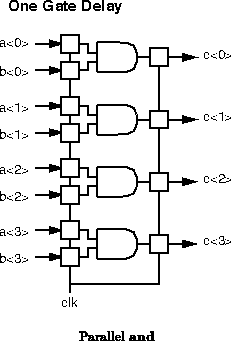
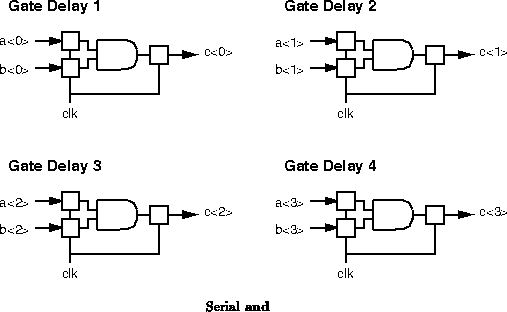
Functional capacity is a space-time metric which tells us how
much computational work a structure can do per unit time. Correspondingly,
our ``gate-evaluation'' metric is a unit of space-time capacity. That is,
we can get 4 ``gate-evaluations'' in one ``gate-delay'' out of 4 parallel
and gates (Figure ) or in 4 ``gate-delays'' out of
a single and gate (Figure
).
That is, if a device can provide capacity gate evaluations per
second, optimally, to the application, a task requiring
gate
evaluations can be completed in time:
In practice, limitations on the way the device's capacity may be
employed will often cause the task to take longer and the result in a lower
yielded capacity. If the task takes time , to perform
, then the yielded capacity is:
The capacity which a particular structure can provide generally
increases with area. To understand the relative benefits of each computing
structure or architecture independent of the area in a particular
implementation, we can look at the capacity provided per unit area. We
normalize area in units of , half the minimum feature size, to
make the results independent of the particular process feature size.
Our metric for functional density, then, is capacity per unit area
and is measured in terms of gate-evaluations per unit space-time in units of
gate-evaluations/
. The general expression for
computing functional density given an operational cycle time
for a unit of silicon of size
evaluating
gate evaluations per
cycle is:
This capacity definition is very logic centric, not directly accounting for interconnect capacity. We are treating interconnect as a generality overhead which shows up in the additional area associated with each compute element in order to provide general-purpose functionality. This is somewhat unsatisfying since interconnect capacity plays a big role in defining how effectively one uses logic capacity. Unfortunately, interconnect capacity is not as cleanly quantifiable as logic capacity, so we make this sacrifice to allow easier quantification.
As noted, the focus here is on functional density. This density metric tells us the relative merits of dedicating a portion of our silicon budget to a particular computing architecture. The density focus makes the implicit assumption that capacity can be composed and scaled to provide the aggregate computational throughput required for a task. To the extent this is true, architectures with the highest capacity density that can actually handle a problem should require the least size and cost. Whether or not a given architecture or system can actually be composed and scaled to deliver some aggregate capacity requirement is also an interesting issue, but one which is not the focus here.
Remember also that resource capacity is primarily interesting when the resource is limited. We look at computational capacity to the extent we are compute limited. When we are i/o limited, performance may be much more controlled by i/o bandwidth and buffer space which is used to reduce the need for i/o.
Functional density alone only tells us how much raw throughput we get. It says nothing about how many different functions can be performed and on what time scale. For this reason, it is also interesting to look at the functional diversity or instruction density. Here we use functional diversity to indicate how many distinct function descriptions are resident per unit of area. This tells us how many different operations can be performed within part or all of an IC without going outside of the region or chip for additional instructions. We thus define functional diversity as:
To first order, we count instructions as native processor instructions or processing element configurations assuming a nominally 4-LUT equivalent logic block for the logic portion of the processing element.
Space must also be allocated to hold data for the computation.
This area also competes with logic, interconnect, and instructions for
silicon area. Thus, we will also look at data density when examining
the capacity of an architecture. If we put of data for an
application into a space,
, we get a data density: