Previous: Interconnect Up: Structure and Composition of Reconfigurable Computing Devices Next: RP-space Area Model
The need for instructions to control device operation is one distinguishing feature of general-purpose computing devices. These instructions give general-purpose devices their flexibility to solve a variety of problems. At the same time, instructions require dedicated resources for storage and delivery.
General-purpose computing architectures must address a number of important questions:
In this chapter, we look at the problem of instruction control and
the resources involved. We start by looking at the extreme case where
every bit operation is given a unique instruction on every cycle. This
example illustrates that instruction distribution resource requirements can
be quite large -- dominating other areas in a device. To combat these
requirements, traditional architectures have placed various, stylized
restrictions on instruction distribution in order to contain its resource
requirements. Each of these restrictions also limits the realm of
efficiency of the architecture. We review these restrictions and their
effects on device utilization efficiency in Section . Of
course, the opportunity to compress instruction distribution requirements
depends on the inherent compressibility of the instruction stream
suggesting that some computations will remain description limited while
others are compute limited (Section
). We also look
at the issue of instruction stream control (Section
).
Finally, Section
organizes the architectural parameters
reviewed in this chapter into an expanded taxonomy for multiple data
processing architectures.
Consider that we have bit processing elements. Each of
these elements may be a 4-LUT as in the previous section or a one bit ALU.
We want to provide a different instruction to each processing element on
every cycle of operation. From Section
, we see that
100 MHz+ operating frequencies are readily achievable today, with many devices
already achieving higher frequencies. We will consider a 200 MHz operating
frequency as one that will be easily achievable in the very near future.
We saw from Section
that each 4-LUT needs 40-50 bits to
describe its network configuration and 16 bits to control the logic
function. We will thus assume each LUT requires a 64-bit instruction to
control it.
Let us further assume that we distribute the instruction, one per
clock cycle, from all four sides of the array of processing elements
densely using 2 layers of metal with an 8
wire pitch.
Of course, the assumption that we dedicate two full metal layers to
instruction distribution is extreme, but even making this best
case assumption, we will see that the resources required for full
instruction control can dominate all other concerns. For the sake of easy
comparison, we will target a
array element, which is on par with large,
conventional 4-LUT FPGA implementations (Table
).
Across the width of one processing element, we can run instruction
distribution busses to control two such elements:
This means, we can support an array with 2
as many processing
elements (
) as it has edge widths. That is:
From which we conclude
.
At this point, we have fully saturated the i/o bandwidth into the compute array. Any further increase in the number of elements supported in the array must be accompanied by a corresponding increase in LUT size. That is:
Consequently, LUT area increases linearly with the number of processing
elements supported in the array. The instruction distribution
bandwidth requirement is the dominante size effect determining
the density with which computational elements can be built. Notice that
the LUT area growth rate dictated by instruction bandwidth is larger than
the interconnect growth rate for any value of and, ultimately, both
interconnect and instruction distribution compete for the same limited
resource -- wire bandwidth.
Further, we can calculate the actual instruction bandwidth
requirements. At 200 MHz and 64-bit instructions, each LUT requires
1.6GBytes/s of instruction distribution. For the case above, this
amounts to over 100GBytes/s.
This kind of bandwidth could not, reasonably, be supported from off
chip with any contemporary technology, necessitating on-chip instruction
memory. At 1000 per SRAM cell, 16 64-bit instructions will
occupy the same space as each 1M
processing element. If more
than 16 unique instruction sets are required, instruction memory will
occupy more area than the processing elements and interconnect.
In the previous section we assumed 64 bits per instruction. This seems to be a reasonable, ballpark estimate of the number of bits required to describe a single bit operation, including interconnect.
Section showed us that we cannot afford to
have full, independent, cycle-by-cyle control of every bit operation
without instruction storage and distribution requirements dominating all
other resource requirements. Consequently, we generally search for
application characteristics which allow us to describe the computation more
compactly. In this section, we review the most common techniques generally
employed to reduce instruction size and bandwidth. We see that every
architecture reviewed in Chapter
exploits one or more of
these compression techniques.
Processors do not, commonly, operate on single bit data items.
Rather, sets of bit elements (
) are grouped together
and controlled by a single instruction in SIMD style. This has the effect
of reducing instruction bandwidth requirements and instruction storage
requirements by a factor of
. This compression scheme takes advantage
of the fact that we commonly do want to operate uniformly on multibit
quantities. We can, therefore, effectively amortize instruction resources
across multiple bit processing elements.
Returning to our opening example, we can support more
processing elements before reaching the same point of wire saturation:
The utilization efficiency of the resulting architecture depends on
the extent to which all operations are -bit operations, or even
multiples thereof. When smaller operations,
, are required,
bit processing units will sit idle while only
units provide
useful work.
SIMD and vector machines take this instruction sharing one step
further. They arrange so that multiple functional units operating on
nominally different words share the same instruction. This allows them to
scale up the number of bit operators without increasing the word
granularity or instruction bandwidth. It does, however, increase the
operation granularity. To remain efficient now, the application requires
-bit operations, where
, is the number of word-wide datapaths
controlled by each instruction.
Reconfigurable architectures, such as FPGAs, take advantage of the fact that little instruction bandwidth is needed if the instructions do not change on every cycle. Each bit processing element gets its own, unique, instruction which is stored locally. However, this instruction cannot change from cycle to cycle. A limited bandwidth path is used to change array instructions when necessary.
There are two viewpoints from which to approach the efficiency of this restriction:
For the frequency of change case, partial reconfiguration can reduce the reload time by allowing individual processing units to change instructions without requiring an entire reload of all instructions in the array. This can increase reload efficiency if a large fraction of the instructions does not change. Partial reconfiguration can also allow portions of the array to change their instructions while other portions of the array continue to operate. Modern FPGAs from Plessey [Ple90], Atmel [Atm94], and Xilinx [Xil96] support partial reconfiguration for these reasons.
A hybrid form of instruction compression is to broadcast a single
instruction identifier and lookup its meaning locally. This allows us to
use a moderately short, single ``instruction'' across the entire array in a
manner similar to SIMD instruction broadcast. Each processing element
performs a local lookup from the broadcast instruction identifier to
generate a full length instruction. DPGAs (Chapter ), PADDI
[CR92], and VLIW machines with an independent cache for each
functional unit, exhibit this kind of hybrid control.
This technique is similar to a dictionary compression scheme where the set of entries at each ``instruction'' address makes up one element in the dictionary. The instruction address is the encoded symbol which can now be transmitted into the array with minimal bandwidth. The key benefit here is that the parallel instruction sets can be tailored to each application in the same way the dictionary can be tailored to a message or message type.
Efficiency in this scheme is similar to the task critical path
length case above. The difference being, that each single processor need
not be dedicated to a single instruction. With local instruction stores
each holding instructions, an array of
processing nodes can
perform up to
different bit operations. In the single
instruction configuration case, a critical path of
implied a
peak, achievable efficiency of
. In this case, the
peak, achievable efficiency is
.
Viewed in terms of instruction change frequency, the additional local configurations can serve as a cache, diminishing the need to fetch array instruction from outside the array. Like a cache if each instruction set required is unique, it will provide no benefit. However, when an array instruction can be kept in the array and used several times before being replaced, we reduce the required instruction bandwidth. Use of a loaded instruction can occur at the operational cycle rate rather than at the bandwidth limited reload rate.
With multiple configurations it is possible to arrange for
instruction reload to occur as a background task operating in parallel with
operation. If the reload time, , is less
than the run time within the balance of the loaded instruction memory,
, and the next instruction can be predicted
sufficiently in advance, reload time can be completely overlapped with
computation.
Since it is unlikely that all instructions will be used with equal
frequency, one can break instructions into a series of smaller words,
giving common instruction short encodings. If we huffman encode our
instruction into a series of -bit words, we can, potentially, reduce the
instruction distribution bandwidth by a factor of
; that is,
if we
assume 64 bit instructions.
The efficiency now depends on the expected number of -bit words
required to construct a single, logical instruction. If the instruction
stream entropy is low, this kind of encoding can be very efficient -
asymptotically approaching one symbol per instruction. Counterwise, if the
instruction stream entropy is high -- or even flat, it may take a full
cycles to built up a single
instruction. Worse, if the instruction frequency is substantially
different from the instruction frequency for which the encoding was
optimized, it can actually take more cycles, on average, to build an
instruction. Of course, the huffman encodings could be variable, as well,
to avoid this mismatch, but the space required to handle programmable
huffman encodings will likely exceed the area of several computational
units.
All of the bits in an instruction do not always need to change at once - or portions of an instruction may change at different rates. Rather than include the infrequently changing portions of the instruction in the word which is broadcast from cycle to cycle, these portions can be factored out of the broadcast instruction and explicitly loaded with new values only when they need to change. This allows us to describe richer instructions with less bandwidth. These locally configured instructions can be seen as a special case of the previous section on likelihood encoding - but in this case we exploit the low frequency of change rather than simply the low frequency of occurrence of some instructions.
Mode bits such as these are used to define operational modes in several architectures. Floating point coprocessors often use mode bits to define rounding modes. Segmented SIMD architectures such as Abacus [BSV +95] and the dynamic computer groups of [KK79] use mode bits to define segmentation of the SIMD datapaths.
Bandwidth savings depends on the number of bits factored out of the broadcast instruction stream. Efficiency depends on the frequency with which non-broadcast instruction values need to change. Typically, it takes an instruction cycle to load each mode value -- which is an instruction cycle which does not serve a purpose towards execution.
Two major themes emerge from the techniques listed here:
Of course, we can only succeed in compressing the instruction
bandwidth when there is structure to the task description for us to
exploit. If the task descriptive complexity really is as large as implied
in Section , we are instruction bandwidth limited, and
instruction distribution does determine achievable, computational density.
This suggests we have two extremes in the characterization of computing tasks:
As with most compression schemes, the amount of compression achievable, in practice, also depends heavily on the frequency of repetition and storage space available. For example, if a task performs a sequence of one million, unique operations, then restarts the sequence, the stream is very repetitive, and an infinite sequence of such such repetitions contains a constant amount of information. However, unless we have space to hold all one million instructions on chip, we will not be able to take advantage of this regularity and low information content in order to compress instruction bandwidth requirements. Further, holding one million instructions on chip is a large cost to pay for instruction storage, even by today's standards.
In Sections and
, we viewed the
set of processing elements as having a single, large, array-wide,
instruction. In general, the array-wide instruction context may be
decomposed into a number of independent instruction streams. This
decomposition does not change the aggregate instruction bandwidth which may
be required into the array, but it may change the number of distinct
contexts used by the array and hence the requirements for instruction
distribution and storage.
Let us assume, as in the case of Section , that
each processing element has a local store of
instructions. Let
us also assume we have a series of
independent tasks, each composed of
at most
instructions. The total number of distinct, array-wide
contexts may be as large as
, since the tasks are
independent and any combination of instructions is possible. If each of
the tasks is controlled separately, we need only
instructions to describe and control the tasks. If we must control the
tasks with a single instruction stream, that stream requires all
contexts and hence a larger number of
instructions,
, are required.
This example demonstrates that there is a control granularity which
is a distinct entity from the operation granularity introduced in
Sections and
. As with
operation granularity, we can compress instruction control requirements by
sharing the control among a number of operating units. However, if we
control too many units by the same control stream, we are forced to use the
device inefficiently. In the worst case, we may pay an efficiency or
compaction penalty in proportion to the product of the instruction sets of
the independent operations which must be combined into a single control
stream.
The separate streams of control are, of course, what distinguishes
MIMD architectures (Section ), as well as MSIMD ( e.g.
[Nut77][Bri90]) or MIMD multigauge [Sny85]
architectures.
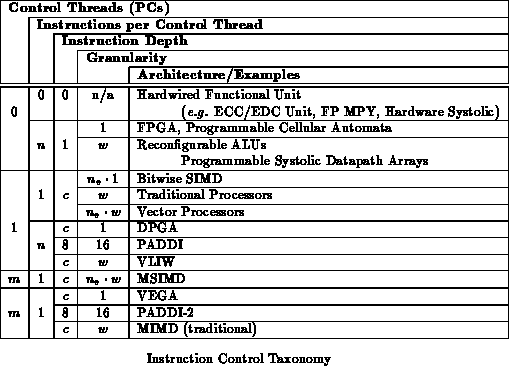
Table categorizes the various architectures we
have reviewed in Chapter
according to the granularity
(
,
), local instruction storage depth (
), number of distinct
instructions per control thread (
), and number of control threads (
)
supported. This taxonomy elaborates the multiple data portion of Flynn's
classic architecture taxonomy [Fly66] by segregating
instructions from control threads and adding granularity.
In this section, we have seen that the requirements for instruction
distribution and storage can dominate all other resources on
general-purpose computing devices, dictating the size and density of
computing elements. A major distinguishing feature of modern,
general-purpose architectures is the way in which they compress the
requirements for instruction control. Traditional microprocessors, SIMD,
and vector machines reduce the requirements by sharing a single instruction
across many bits or words. FPGAs and programmable systolic arrays reduce
requirements by maintaining the same instruction from cycle to cycle.
VLIW-like architectures use small, local instruction stores addressed by
short addresses so that limited instruction distribution bandwidth can
effect cycle-by-cycle changes in non-uniform instructions. Each of the
techniques used to reduce instruction control resources comes with its own
limitations on achievable efficiency should the needs of the application
not meet the stylized form in which the instruction bandwidth reduction is
performed. Some instruction sequences are more compressible than others,
suggesting we have a continuum of task descriptive complexities such that
some tasks are, by nature, instruction bandwidth limited while others are
parallel computing resource limited. In this chapter we reviewed both the
nature of the resource reductions and the efficiency limits which arise
from these techniques. In the following chapter, we will combine these
effects with our size and growth observations from Chapters
and
to model the size and efficiency of reconfigurable
computing architectures.