Early Processor Ideas
Andre DeHon
Tom Knight
Original Issue: May 1990
Last Updated: Tue Nov 9 12:37:36 EST 1993

This note documents some early thoughts on a potential processor architecture for Transit. At this point in time, this is mostly a collection of ideas rather than an architectural specification. Ideas and counterproposal are welcomed.

The processor will support the concurrent operation of several basic
functional units. Concurrent execution within functional units will be
compiler controlled effecting a long instruction word style super scalar
processor. As shown in Figure , the current design includes four
independent functional units: a generic ALU, an address ALU, a flow control
unit, and a load/store interface. The processor will be organized in a
pipelined RISC architecture.

Externally, the processor has separate address and data paths for
instructions and data (Figure ).
Register bypass paths will allow results to be used before they can be written back to memory.
It might be worthwhile to support register windows in addition to multiple contexts. If one believes the claims of SPARC fans and architects, register windows offer considerable benefit for speeding function calls ([Sem90] [H +86] et al.). Pages 450-454 of [HP90] provides a consice description of some of the pros and cons of register windows in special circumstances. That discussion, however, is limited to single context processors without implicit floating point support.
[Kub90a] presents the best argument I have heard against the use of register windows in a rapid context switched processor. Basically, register windows dramatically increase the size of the state associated with a single context. This directly translates to a significantly larger cost for loading and unloading contexts from the processor.
We should think about how much additional area and complication register windows would require as well as their potential value.
We will need the ability to specify no register for operations that do not require all of the register fields provided by the architecture. For speed and ease of decoding, we probably do not want to condition the use of register fields on the opcode. Providing extra bits to indicate implicitly whether or not to use a register field is probably excessive. One way to specify no register with no extra bits is to have a dummy or hardwired register to use in all cases where we wish to specify no register for a particular register field.
MIPS-X used register r0 in this manner [Cho89]. r0 would provide a constant 0 when used as an input about which an operation cared. Writes to r0 are simply ignored. In this manner, they define noop as add r0,r0,r0.
With at least two ALU's, and perhaps other portions of the processor,
generating condition codes simultaneously, it may be quite worthwhile to
have a small (4 or 8 element) condition register file. This will also
allow condition codes to be stored across multiple operations for increase
branching flexibility. The condition code register file would need
multiple context support similar to the data register file described in
Section .
There is a choice as to what actually gets stored in the condition code registers. One option is to simply store all the condition bits. When it comes time to use the condition codes, a register is read and the desired binary value is computed/extracted from the condition code. In this case, conditional branches look like:
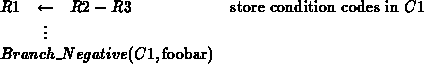
Alternately, the desired condition bit can be selected when the condition code store operation is performed. In this case, only a single bit is stored. When the condition code is used, the stored value can be used directly. In this case, branches look like:

The first option affords more flexibility than the later. The basic difference is where the logical bit decode/extract occurs. In the second, it occurs between the condition code computation and storage, while in the first it occurs between the condition code read and the branch. In the second case, with less decoding, it may be possible to get away with less branch delay slots than current RISC architectures.
Obviously, this requires more thought.
[Perhaps condition codes can be stored in the normal register file by making the register file wider and using the extra bits added to each register to store condition codes. -- TK]
The instruction dispatch unit fetches instruction from the I-cache and starts them in the pipeline. When a data word is encountered in the instruction stream, the data word is written into a fixed register ( r31?). Ideally, this write should be able to progress in parallel with the next instruction dispatch. That is, the write of a constant datum into a register should not require its own cycle through the processor. In order to allow the data write to progress in parallel with instruction execution, the instruction dispatch unit will have to look at the next two instructions in the instruction stream and dispatch both accordingly when appropriate.
The dispatch unit will also have to deal with branches and misses in the I-cache. Not much thought has gone into these details, yet. This certainly requires further thought.
The generic ALU is capable of performing basic logical operations on all data types. As long as the data types are appropriate for the specified operation, the generic ALU will perform the requested calculation. As such, the generic ALU should handle both floating and fixed point arithmetic. Floating point arithmetic should conform to IEEE-754 [Com85]. When argument types are mismatched or inappropriate for the requested operation, the ALU will trap.
The generic ALU requires three inputs to allow operations such as:
Two write ports allow single cycle execution of operations such as:
If these two operations are the most data intensive, perhaps we could get
away with two read ports, one write port, and one read/write port.
The Address ALU is a simple integer logic unit for performing effective address calculations. There is probably no reason it cannot be used to perform simple arithmetic operations such as index calculations and tests. Since the address ALU does not perform complicated instructions, it can get by with a single write port and two read ports from the register file. The address ALU should also be capable of trapping the processor when appropriate.
The external memory interface supports load/store operations to the off-chip memory systems. (tn13) suggests a set of basic memory transactions it might support.
Assuming we can achieve a smooth, single-cycle context switch
(Section ), it might prove beneficial to allow the external
memory system to inform the processor when pending memory operation can
complete (have completed).
To allow this signalling, we provide the external memory system a
signal line which it can assert when a memory operation completes. Along
with this, we provide it with a bus so it can indicate the context
associated with the response.
The same bus can be used during memory operation to indicate the context
associated with the memory operation. N.B. Since this bus
is shared by the processor and memory system, it is not possible to both
indicate a response and perform a memory operation which could fail to
complete
in the same cycle. For this reason, the memory system will
have to wait slightly into the cycle before driving the bus to give the
processor the first opportunity to use the bus. Perhaps a separate signal
is needed which the processor will assert early in the cycle to indicate
its desire to use this bus during the cycle.
When a memory operation fails to complete, the processor does not advance the pipeline to the next stage for the current context. The memory system notes the context of the pending operation. The processor continues execution on a different context during the next clock cycle by resuming the contexts pipeline. When the memory system is ready to complete the pending operation, it signals the processor with the associated context identification. The processor completes the current clock cycle. In the following clock cycle the processor resumes execution on the original context. Since the pipeline for this context was not advanced, the execution resumes with the pending operation. This operation should now complete, and the context can continue execution.
If this scheme is practical, it may not be necessary to distinguish between cases in which blocked operations should busy wait and cases in which they should context switch. With single-cycle context switches and the ability to resume a context as soon as the memory system is capable of allowing the context to continue, busy waiting offers no advantages over context switching. It will always be appropriate to switch contexts.
But what about multiple outstanding memory operations and responses?
For this to be practical and efficient, the processor will have to be
able to deal with the case in which it has multiple contexts waiting on the
memory system. This, of course, means the memory system could complete
these operations in rapid succession and the processor must be able to
handle this case in a reasonable way.
Additionally, if this scheme is to replace busy waiting, there will need to
be some provisions for assigning priorities to contexts.
It is perhaps worthwhile to note that the scheme just presented
(Section ), can deal with successive replies from the memory
system. Upon getting a reply, on the next processor cycle, the processor
switches to the indicated process and completes the operation.
The earliest the memory system can provide the next response to the
processor is in the next cycle in which the processor does not use the
context bus. At this point, the memory system can indicate the next
pending response and the processor can switch to that process and complete
its pending operation. In this manner, pending operations can be completed
as soon the memory system can indicate a response.
N.B. This does expose one potential problem. Since, the processor is capable of issuing a load/store operation on every processor cycle and the memory system cannot indicate a response while the processor is attempting many of the load/store operations, the processor could prevent the memory system from providing timely responses.
Whether or not this really poses a problem will depend on what common sequences of operations are. Is it likely for the load/store unit to be busy for long periods of time without a break in which the memory system can respond?
This could certainly be dealt with by providing separate busses for the processor and memory system to use in indicating context. That solution begins to sound a bit costly in terms of pin requirements.
I like the idea of allowing the memory system the ability to indicate a response on every processor cycle. I would advocate that scheme if it can be done in a way which is not prohibitively costly. Even in such a case, the processor could handle continuous response streams. It would simply complete an operation in one context. During that complete it would receive the next indication of a completion. The next processor cycle would be on the context with the newly completed memory operation. This could complete and possibly get another completion indication. This sequence could continue in this manner. Since there are only a small number of contexts actually active in the processor, the number of successive responses would be likewise limited.
For dealing with both memory responses and the more general issue of selecting a beneficial context to run, it might prove useful to have a ready/waiting flag for each context. When the context switches because of an outstanding memory operation, the bit would be set to indicate the context is waiting for a response. When the memory system indicates it is ready to complete the operation, the bit could be cleared. This would happen whether or not the processor decided to switch back to that context. With these flags, the processor could avoid resuming contexts which were waiting for pending memory operations. Additionally, the processor would have a way of acknowledging the completion of memory operation when it was not going to immediately switch contexts to take advantage of the completed operation.
Of course, we would like to do as little scheduling and priority work in hardware as we can get away with. This could become quite intricate very quickly and certainly is not well understood. Some thoughts:
Pending memory operations should be serviced quickly. When the memory
system has gone through the trouble of allocating resources to allow a
memory operation to complete, the processor should take advantage of this.
In these cases, the memory system has probably allocated cache space for an
entry and perhaps even gone through the trouble of obtaining exclusive
access to a memory operation. It would seem most beneficial to make use of
the memory systems efforts as soon as possible. If completing operations are not serviced
immediately, thrashing can occur in certain cache coherence protocols. See
[Cha90] for a detailed description of this kind of thrashing.
A general priority scheme is almost certainly computationally too expensive (and not well understood). However, if we allow context switches out of trap handlers, we probably want to make completing the trap handler a higher priority than running other processes. This may depend on the exact nature of the particular trap invoked.
To summarize, the goals of this memory interface are as follows:
The I-cache is an on chip cache for the instruction stream. This will probably be a direct mapped cache. The size will depend on available space on the chip.
[The I-cache may want to be organized to hold branch targets to minimize the performance degredation when not executing sequential instructions. The sequential instruction fetches can be pipelined. If this is done properly, sequential execution can be satisfied by pipelined memory fetches. No processor stalls occur unless a target of a branch is not in the I-cache. -- TK]
We really do not want to be forced to complete the execution of instructions in the pipeline. We have no way of guaranteeing that the instructions in the pipeline can complete in a short amount of time. Often it is the case that the context is being unloaded because it has encountered an extremely long latency operation. So we really want to be able to simply flush the pipeline and restart at the appropriate address. For this to be possible, it must be the case that processor state is only side-effected in the final pipeline stage.
One question to consider, is how loading and unloading gets done. It might be possible to have a separate unit unloading and reloading contexts in parallel with processor execution. However, this might require too many resources to be practical ( e.g. separate read/write port into the register file, shared access to load/store path (or separate load/store path), access to registers not in current context, non-trivial control unit). Alternately, register loading and unloading can be done explicitly.
Native data size will be at least 64 bits wide in order to provide
efficient IEEE double percision floating point support. Complete data size
may be wider to support tagged data. Instructions will also be tagged and
will almost certainly be the same size as primitive data objects.
(tn12) documents thoughts on instruction and data format for the
processor.
[ Another option for instructions, is to use separate, shorter instructions. The instruction dispatch unit can look at some number of instructions and dispatch as many in a single cycle as possible. That is, perform some dynamic and out of order instruction execution like Intel's 80960CA [MB88] [Int89c] [Int89a] [Int89b]. This scheme is highly dependent on the ``window-size'' of instructions the processor will look at each cycle. The perfomrance will, of course, depend on the arrangement of data in the instruction stream. Presumably, it will be just as easy to arrange a sequence of instruction which can exploit maximal concurrency as it is to create one long instruction word. -- AMD]
We are aiming at a very fast (cheap) context switch. Ideally, we want
to achieve a smooth immediate context switch between cycles. There should
in general be no overhead in switching context.
To achieve this fast of a context switch, we take advantage of the context
support designed into the register file (Section ) and
store the full pipeline state of each context. The entire state of each
active context is available in the processor. Changing contexts is
effected by simply changing the context pointer. Changing the pointer
selects the new set of state and execution on the new context can begin
immediately. With this scheme, there is no need to flush the pipeline
during context switches. The entire pipeline state is preserved until the
context is resumed and the state is once again needed.
An option will still be provided to clear the pipeline when necessary. This will probably be necessary when unloading a context from the processor and perhaps during certain exceptions.
Of course, only a finite number of contexts can be actually loaded on the
processor at one time. This fast context switching is only possible among
the loaded contexts. To switch to an Unloaded context, the context must
first be loaded (see Section ), which may require unloading a
context to make room for the new context. The operation of unloading and
loading contexts will be slow compared to context switching among loaded
contexts.
As with any pipelined processor, the basic conceptual pipeline stages are:

These pipeline stages do not necessarily correspond to the actual breakdown in stages in the physical processor. That breakdown will be dependent on technology used and numerous details which have not been considered, yet.
Fetch will take instructions from the internal I-cache and prepare them for execution. When instructions miss in the internal I-cache, the fetch operation will probably require additional processor cycles to complete. One possibility for I-cache miss behavior is to stall the processor and perform external cache fetches in a manner similar to the MIPS-X [Cho89]. Perhaps, though, if we are sufficiently clever we can avoid stalling the entire processor for this case. The behavior of I-cache misses still requires much thought. No explicit instruction decode phase was listed because we expect there to be little or no real decoding to be done. Any decoding should be minimal and fast and fit either at the end of the fetch phase or at the beginning of the read phase.
Read simply obtains the appropriate values from the registers, including register bypassing when necessary.
All operations are actually performed during the ALU/EMEM stage of the pipeline. Since loads and stores occur simultaneous with computational operations, no address computation is performed as part of the a load or store. The actual address must be computed and placed in a register by a previous instruction. The ALU/EMEM phase is likely to require significantly longer than the other operations; it may need to be subdivided into multiple stages to balance the pipeline.
Write places the results of all computations and load operations into
the appropriate registers in memory. As discussed in Section ,
the processor state, aside from the pipeline state, should only be updated
during the final pipeline stage ( write).
Here, we briefly consider one possible branching scheme. Alternate proposals are quite welcome.
The table below shows a rough diagram of instruction progression through the pipeline stages. The exact progression, of course, depends on the actual breakdown of the pipeline stages.

The result of a conditional is determined and ready to be written into the
condition code register at the end of an ALU/EMEM cycle ( A). At
earliest, the condition code can be used during the subsequent cycle; that
is, with bypass paths, it is available during the write ( W) cycle.
If instruction is a conditional, its value can be read at earliest in
cycle 4. This means instruction
, which is in the read ( R)
phase at this point is the first which can use this result. Now, if we
allow branching control to take place in the read phase, a branch
instruction at
can change the PC. If we can arrange for this
to occur early enough in the cycle, this change can take effect for
instruction
which is currently in the fetch ( F) phase. This may
require too much in a single cycle. In which case, it will be necessary to
perform the update of the PC in instruction
's ALU/EMEM phase
which can at earlier affect instruction
.
If used just like current RISC pipelines, this gives us, at best, the
standard two delay slots. Comparisons take place at instruction and
the change occurs at instruction
. However, we have gained the
freedom of scheduling the comparison earlier in the computation potentially
offering more flexibility than current RISC pipeline schemes.
One implication this scheme has is that the PC is changed during either the read or ALU/EMEM phase and not during the write phase when the rest of the processor state is changed. For flushing the pipeline, we will need to know the last instruction to complete the write phase. Thus we will need to explicitly keep up with the address of each instruction in the pipeline. With this information, the ``early'' change of the PC will not leave the processor in an inconsistent state.
Using register windows (Section ) and some simple
conventions for passing arguments between procedures, we should be able to
avoid much of the overhead traditionally associated with procedure calling.
Perhaps, there is no need even for an explicit procedure call instruction.
A procedure call could be effected by placing the return address in the
appropriate register and branching to the entry for the new procedure while
incrementing the register window pointer. Of course, if incrementing the
register window pointer causes it to overflow, a trap handler will be
invoked to clear out a register window for use. Similarly, the return is
simply a jump back to the address placed in the return register while
decrementing the register window pointer. Similarly, this could cause a
register window underflow trap.
We need to establish efficient call and return conventions and consider the actual compositions of the register windows. We also need to consider if any additional support is needed to speed general procedure calls aside from register windows.
It should be possible to handle traps and exceptions quickly. More specifically, there should be little overhead implicitly associated with entering and leaving trap handlers. Some trap handlers will be for uncommon cases and the speed of their execution will not be critical to performance.
Let us consider a few options for handling traps.
We can reserve one or more contexts for traps. When a trap occurs, the processor:
This allows the trap handler invocation and return to take advantage of the
fast context switching to effect low trap overhead. It probably would not
be too hard in this scheme to get at the actual datum causing the trap; the
trap handler would just have to be able to reference data in the pipeline
by context. However, with the scheme under consideration for supporting
separate register sets for each context (Section ) it
would not be possible
to access
the register set of the trapped context. Additionally, this scheme
probably does not deal with traps within traps very gracefully.
Alternately, traps could be handled much like procedure calls. A new register window could be stacked for executing the trap handler. Trap windows is closely related to the trap context scheme. When a trap occurs in this case, the processor will:
This scheme would probably provide more flexibility in referencing the register set of the trapped process. It would certainly allow for traps within traps. However, this would require handling window overflow traps in some special manner since it will be impossible to allocate a trap window when the trap is a window overflow trap. Similarly, a trap could cause a window overflow trap. This need for special handling for window overflows probably makes this option too quirky to consider. Additionally, since the pipeline must be flushed when the trap handler is invoked, this scheme will generally require more overhead in switching to the trap handler.
Perhaps a hybrid of the two proposals would work best. Traps would generally be handled by switching to a trap context. When a trap occurred within a trap, the processor would stack a new register window to handle the most recent trap. This still has problems with referencing the register set of the trapped context. It has minimal overhead for handling single level traps. For multiple level traps, the hybrid scheme suffers the additional overhead associated with the trap window scheme due to the need to flush the processor pipeline. However, since this is probably a more exceptional case, the additional overhead is tolerable. The anti-symmetry in trap behavior could prove to be a real headache. i.e. Sometimes a trap is running in a separate context and sometimes it is simply running in a new window. The detailed behavior in both cases would be somewhat different. Additionally, care would have to be taken to avoid window overflow.
One of the gross problems that remains in most of these schemes is that of properly handling traps within traps. Following is a quick summary of how this is handled in a number of existing machines.
I'm not convinced any of these schemes is fully acceptable. Hopefully, this discussion will inspire further consideration and the development of cleaner alternatives.
Many of these proposals and schemes were heavily influenced by the Alewife Project and their work on APRIL and SPARCL [ALKK90]. I have freely borrowed what I consider their better ideas. I am grateful for many of the issues they have raised.
Many of the considerations presented here have benefitted greatly from numerous discussion with John Kubiatowicz.