Entropy, Counting, and Programmable Interconnect
Andre DeHon
Original Issue: September, 1995
Last Updated: Thu Nov 30 22:09:56 EST 1995

Conventional reconfigurable components have substantially more interconnect configuration bits than they strictly need. Using counting arguments we can establish loose bounds on the number of programmable bits actually required to describe an interconnect. We apply these bounds in crude form to some existing devices, demonstrating the large redundancy in their programmable bit streams. In this process we review and demonstrate basic counting techniques for identifying the information required to specify an interconnect. We examine several common interconnect building blocks and look at how efficiently they use the information present in their programming bits. We also discuss the impact of this redundancy on important device aspects such as area, routing, and reconfiguration time.
Despite the fact that programmable devices ( e.g. FPGAs) are marketed by the number of gates they provide, a device's interconnect characteristics are the most important factors determining the size of the programmable device and its usability. When designing the interconnect for a programmable device we must simultaneously address several important, and often conflicting, requirements:
Fundamentally, interconnect description memory need not grow as quickly as wire and switch requirements. This leaves us with design points which are generally wire and switch limited. We may, consequently, encode our interconnect description sparsely when memory area is nearly free and wiring channels are determining die size. Since interconnect memory grows slowly compared to switch and wire requirements, interconnect memory need never dictate die size for large, single-context, reconfigurable components.
As we begin to make heavy use of the reconfigurable aspects of programmable devices, device reconfiguration time becomes an important factor determining the performance provided by the part. In these rapid reuse scenarios, interconnect encoding density can play a significant role in determining device area and performance.
This paper starts out by identifying a simple metric for characterizing interconnectivity -- a count of the number of ``useful'' and distinct interconnection patterns. While simple, this metric turns out to be difficult to calculate in the general case. We can, nonetheless, analyze a number of common structures to obtain bounds on the number of patterns provided by more complicated topologies. From this analysis we observe that conventional, programmable architectures have highly redundant programming bit streams. The analysis helps us identify opportunities to save programmable memory area and lower reconfiguration time by reducing that bit stream redundancy.
In the next section, we open with a motivational example to illustrate the
issue and analysis. In Section , we define the interconnection
metric more precisely. In Section
, we look at some basic
interconnection building blocks which can be easily analyzed in isolation.
Section
looks at some ideal or pedagogical network structures by
composing the primitives from Section
. Section
touches briefly on the role of placement in interconnect flexibility.
Section
looks at conventional interconnect examples using the
results of Section
to estimate the amount of redundancy these
devices exhibit. We discuss the implications and impact of this redundancy
in more detail in Section
before concluding in
Section
.
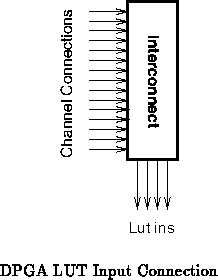
Consider a case where we wish to drive any of sources onto each of
sinks. In our DPGA prototype [TEC +95a], for example,
we needed to drive the 4 inputs to the 4-LUT from the 15 lines which
physically converged upon the LUT cell (
,
, See
Figure
). This kind of structure is typical when
connecting logic block inputs to a routing channel.
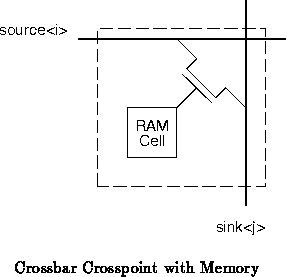
We could provide full connectivity by building a full crossbar between the
sources and
sinks. This requires
, 60 in this
case, crosspoints. If each crosspoint is built with its own memory cell,
as shown in Figure
, this arrangement entails equally
many memory cells.
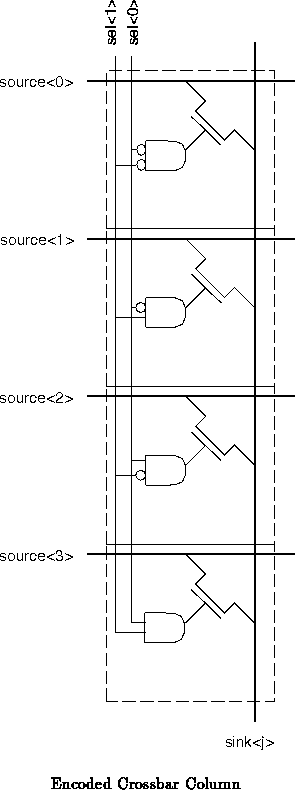
At this point it is worth noting that there are
ways to program 60 memory cells, but many of those connections are not
useful. In fact, of the
memory cells along each input wire, at most
one should enable its crosspoint at any point in time. Since each output
should be driven by one source, there are, in fact, only
,
in this case, combinations which may be useful. We can, in
fact, control the
crosspoints with only
memory cells, or 16 in this case.
Here, each group of
bits serves to
select which of the
inputs should drive onto each of the
output
lines (See Figure
).
If, as is the case for the DPGA, the logic block is a -input lookup
table, even this arrangement provides more routing flexibility than is
necessary. There is, for instance, no need for any of the
inputs to be
the same. Strictly speaking there are at most
(in this example,
) distinct selections of the
inputs from the
sources. This implies we could get away with as few as 11
(
) control bits if we included heavy
decoding.
From this calculation we can also conclude that any combinations provided beyond the 1365 distinct interconnect patterns entailed by the 15 choose 4 combinations are redundant and offer us no additional functionality. This bound is often useful in understanding the gross characteristics of an interconnect. All interconnects which provide all these combinations are functionally equivalent. Above this point we can compare the number of specification bits to the number of requisite specification bits to understand the redundancy in the encoding scheme. For interconnects providing less distinct interconnect patterns, we can compare the number of achievable interconnect patterns to the maximum number of distinct interconnect patterns to get a scalar metric of the flexibility of the interconnect.
In practice, the DPGA prototype used 4, 8-input muxes. This gave it only
32 crosspoints requiring bits to specify the
input. Due to the limited size input muxes, it only supported 1217
distinct input combinations. Our encoding is within one bit of the
theoretical minimum of 11 and routes 89% of the 1365 combinations
identified above. An interesting, pragmatic variant
providing full interconnect is detailed in Appendix
.
With respect to memory bits, we see that dense encoding of the combinations yields a more significant reduction in requisite memory cells than depopulating the crossbar in a memory-cell-per-crosspoint scenario. In an unencoded case, 12 memory bits would not even support a single connection from each of the 15 potential inputs.
Of course, minimizing the number of memory bits does not,
necessarily, produce the smallest layout since dense encodings must be
decoded and routed. We will visit this issue in Section .
This example underscores several issues which are worthwhile to understand when designing programmable interconnect.
The interconnection metric we are focusing on here is to count: the number of unique and useful connection patterns which the network can realize.
With sparse encoding, many bit combinations may be parasitic or non-useful. In the ``bit-per-crosspoint'' example above, we saw that it was not useful to have more than one crosspoint enabled along an output line. In these cases, a large portion of the entire bit stream encoding space refers to interconnection patterns which are at best nonsensical and may even be damaging to the part.
An interconnection pattern which provides the same functionality as
another specifiable pattern adds no capability to the interconnect. That
is, the flexibility which allows both specifications provides no additional
interconnect power. In the example above, we saw that a full crossbar
provided specifiable connections. However, with the
connections feeding into a 4-LUT, a pattern which bring inputs 15, 13, 10
and 7 into the LUT is no different from a pattern which brings inputs 10,
15, 7 and 13 into the LUT. The full crossbar thus provides
redundant patterns which add no functionality to the interconnect.
It is worthwhile to note that interconnect ``flexibility'' as used here can be applied to any interconnection network or family of graphs. As such it is very different from the interconnect flexibility defined in [RB91] [BFRV92] which is used to describe the level of population of switches in a particular interconnect family.
It is important that we look at the interconnection patterns as a whole
to understand which patterns are functionally identical.
Again, looking at the -LUT input selector in isolation from the logic
block, we can identify more distinct patterns than we see when viewed in an
ensemble.
It is also significant that the metric looks at the ensemble of
interconnections feasible rather than looking at the interconnect
flexibility afforded to a single input in isolation. Since resources are
typically shared, the focus on patterns accounts for the limited
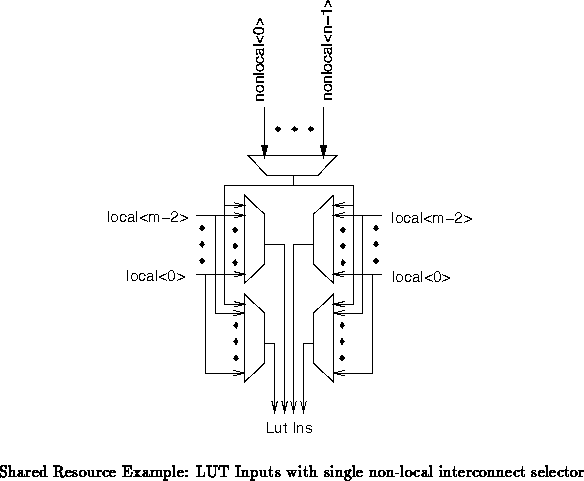
availability of shared resources. For example, consider a shared,
non-local interconnection line as shown in the interconnect fraction
depicted in Figure . Looking at a single input, we see
that the input can come from any of the
local inputs or any of the
non-local inputs. Since the shared line is made available to all LUT
inputs, any input could use this line to access the non-local inputs.
However, since there is only a single non-local input line, it is not
possible to bring more than one non-local line into the LUT at any point in
time.
In this section we identify a few basic primitives used in building interconnection networks. We count the number of interconnection patterns they provide, as well as relating the abstract primitives to their more physical implementations.
An -input multiplexor (mux) can connect any of its
inputs to its
output. In isolation, the multiplexor realizes
distinct
interconnect patterns, requiring
bits
to specify its behavior.
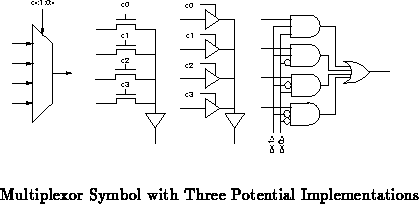
Figure shows a multiplexor and several possible
implementations. Note that a series of tristate drivers attached to a
single, physical wire serves logically as a multiplexor and can be treated
as one for the purposes of analysis. This remains true whether the
tristate drivers have separate or central control. The series of tristate
drivers with distributed control has the additional ability to drive no
value onto the line, but this offers no additional logical functionality
since we can just as easily drive any value onto the output in such a case.
The tristate drivers could also have multiple values driven simultaneously
onto the output, but, unless this is used to perform a logical function,
the multiple drive cases are parasitic rather than useful behavior.
A crossbar has a set of inputs and a set of
outputs and can
connect any of the inputs to any of the outputs with the restriction that
only one input can be connected to each output at any point in time.
Logically, an
crossbar is equivalent to
-input
multiplexors. The crossbar can realize
distinct interconnect
patterns and requires
bits to
specify its behavior. The crossbar represents the most general kind of
interconnect and can often be used to calculate an upper bound on the
flexibility which could be offered by a piece of interconnect.
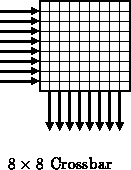
A small crossbars is shown in Figure . We have already seen
some potential implementations in Figures
and
.
With subset selection, we select a group of outputs from
inputs.
We saw this selection when routing the
inputs to a
-LUT. This kind
of selection is also typical when concentrating outputs from one region
down to a limited size channel connecting to another region of the
component. As we saw in Section
, this function
is not as trivially implemented as the crossbar, but the function is
frequently desired making this primitive highly useful for analysis.
Subset selection entails
distinct interconnection patterns and requires
bits to
specify its behavior.
Individual pass gates are too primitive to generally be useful from an analysis standpoint. Alone, each pass gate has 2 interconnection states which can be specified with one bit. From an analysis standpoint it is generally more useful to group collections of pass gates together into a larger structure. As noted above, when the direction of signal flow is apparent, groups of pass gates used to selectively drive onto a single line effectively form a logical multiplexor.
In this section we apply and compose the primitives of the previous section to examine a few families of netlists and networks of general interest.
Let us consider the family of netlists with logic blocks where each
logic block has at most
inputs. Further, the netlist has
inputs and
outputs. To get an upper bound, we assume all logic blocks may provide
a distinct function. In general, each of the logic block inputs may want
any of the
logic block outputs or any of the
inputs. Each output
may come from any of the
logic block outputs. There are
possible interconnect patterns for
the
logic block inputs and
interconnection
patterns for the outputs. All together, there are
interconnection patterns which the netlist
may exhibit. Without exploiting placement (See Section
), if all
interconnects are given equally long descriptions, it will require at least
bits to describe each
interconnection patterns.
In a similar manner, we can look at a device or interconnect and bound
the number of interconnection patterns it provides. Again, assuming we
have logic blocks with
inputs each along with
inputs and
outputs, if we do not allow inputs to be directly connected
to outputs, we have a total number of interconnection patterns of, at most:
If inputs can be directly connected to outputs, we have
possible output patterns for a total number of interconnection
patterns bounded by:
For many devices, each inter-chip i/o pin can
serve as either an output with enable or an input. We thus let ,
assuming we may have to route both the output and the enable for each
physical pin, and have a total of at most
interconnection patterns. The interconnect can thus be
specified with
configuration bits.
From this and the previous example, it is worth observing that network
configuration requirements are growing as --- assuming
is fixed and
grows at most linearly in proportion to
. We can
compare this to the configuration requirements for the logic which are
growing as
. We can also compare this with the number of crosspoints
or total length of interconnect wire which is growing as
if we
are going to provide the full interconnect to support any of the possible
-node netlists.
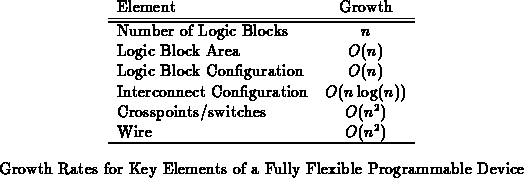
These general observations, summarized in Table , are
worthwhile to remember. Asymptotically, they tell us wires and crosspoints
will be the pacing items for offering flexibility in programmable devices.
They also tell us to expect interconnect programming to grow faster than
logic cell programming. We can describe any interconnect much more
cheaply than we can spatially route it, underscoring the need to
reuse physical crosspoints and wires in time as we build larger
programmable devices and systems.
If a device's network is built entirely out of -LUTs, we can get a
slightly tighter bound on the number of interconnection patterns provided.
Again, our source of inputs is the
LUT outputs and the
inputs.
Each LUT must choose
inputs from
sources. Together, this makes
for
total
interconnection patterns. If we also
assume
and outputs can come directly from inputs, the total number
of interconnection patterns is at most:
The difference between this case and the previous is that the network, sans
output connections, has at most patterns rather than
.
The ratio between these two expressions is:
For large
and small
,
.
This ratio is then roughly
. In terms of configuration
bits, this amounts to
--- a small savings linear in
for
fixed
. e.g. for
, one can save at most 4-5 network
configuration bits per LUT by exploiting the input pin equivalences.
Referring back to Table
, this tells us that exploiting LUT
input equivalences saves us
configuration bits, but does not,
fundamentally, change the growth rate for interconnect configuration.
disjoint_networks.tex
limited_bisection.tex
Once we identify a level of desired interconnect flexibility, it is not
necessary for the physical interconnection network to solely provide that
flexibility. In programmable devices, we also have freedom in where we
place functions and results within the interconnection network. The net
result of this freedom is that we can achieve a given flexibility
with a network which provides fewer than
interconnection patterns. This also means we could, in theory at least,
use less than
bits to specify the
interconnect pattern when we observe that the placement of functions and
results relative to the network also gives us a degree of specification
freedom.
To make this concrete, let us consider a very simple interconnection
problem where we wish to interconnect 4 2-input LUTs (,
).
We know there are
possible interconnection networks for this small example.
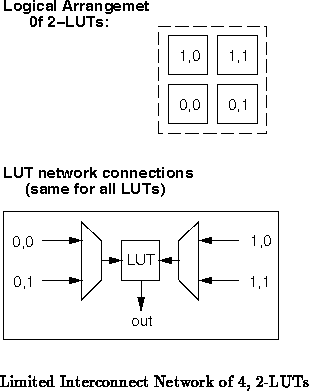
First, we consider a limited interconnection network where we arrange the
four LUTs into a array. Each LUT has one input which may come
from either LUT in the first column and a second input which may come from
either LUT in the second column (See Figure
). Each of the
inputs in this restricted interconnect can come from one of
two places, making for a total interconnect flexibility of
. It
is also worthwhile to note that all 256 interconnect combinations are
distinct. If we had fixed the placement of the 4 logic functions in the
array, then we could only realize these 256 interconnect patterns.
Allowing the functions to be arranged within the array allows greater
flexibility. We know there are
ways to place 4 logic functions in
the
array. Because of the high symmetry of the physical
network, it turns out that groups of 8 permutations are equivalent with
respects to routing. As a result there are 3 distinguishable placement
classes. This could provide us with at most
interconnection patterns if all of the permuted interconnects were
distinct. In practice, this gives us 720 of the 1296 possible patterns.
Using an alternate interconnection scheme with less symmetry, shown in
Figure , we can get 6 distinguishable placement classes
and achieve 1104 of the 1296 possible patterns. The 1104 interconnection
patterns are, of course, over a factor of four more patterns than the 8
bits of interconnect programming could specify, alone.
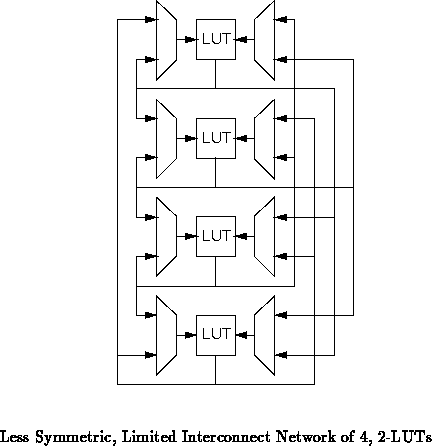
This example underscores the fact that placement in asymmetric networks allows us to expand the number of realizable networks for a given, limited, physical interconnect. Additionally, we see that successfully routing networks in this scheme requires picking the correct permutation for the network (placement) and then the correct interconnection pattern (routing). Asymmetry in the network can have the effect of both increasing the flexibility, by making more interconnection patterns realizable, and of making the routing problem harder, by offering a larger space of distinct placement classes to explore during routing. In general, the extent to which placement can reduce the demand for interconnect resources, including wires, switches, and configuration bits, remains an open issue.
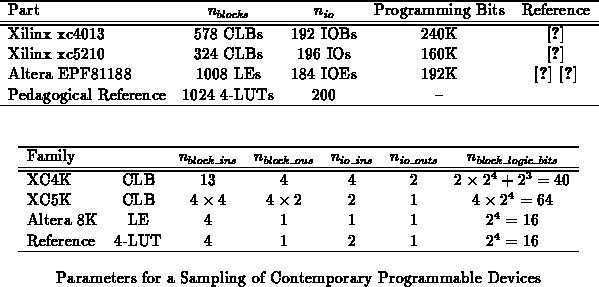
Table summarizes the major characteristics for several
contemporary programmable devices. Additionally, a pure 4-LUT design is
included for sake of comparison with the industrial offerings. We can make
a rough, back-of-the-envelope-style computation on the bits required to
configure the network by making the assumption that the network does
support all potential networks without exploiting placement flexibility.
That is, we assume that the basic logic blocks are fully connected. Since
the conventional offerings are far from being fully interconnected, this
gives us an upper bound on the number of network configuration bits.
Adapting Equation
and taking the base two logarithm to
convert to bits, we get:
We can also calculate the number of bits required to specify the logic block functions in the obvious manner:
Table summarizes the results of these basic
calculations for the identified components.
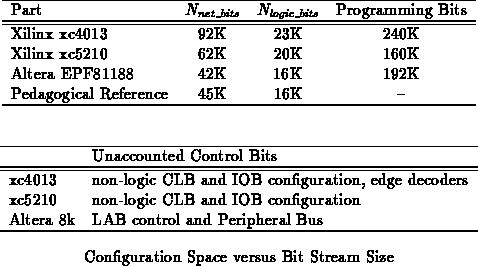
The comparison is necessarily crude since vendors do not provide detailed
information on their configuration streams. However, we expect the
unaccounted control bits in Table to not be more than
10% of the total device programming bits. With this expectation, we see
that these devices exhibit a factor of two to three more interconnect
configuration bits than would be required to provide full,
placement-independent, logic block and i/o interconnect.
We can, of course, derive a tighter bound for the reference 4-LUT design
by adapting Equation :
For the 1,024 4-LUT case identified above, ,
saving roughly 5 bits per LUT as suggested in Section
.
Eight of the 13 inputs on the XC4K go into 4-LUTs and all 16 of the XC5K
inputs go into 4-LUTs. Consequently, all of these arrays require
comparably fewer network configuration bits. The 4 inputs on the Altera 8K
LE also go into a 4-LUT. Since one input may also be used in a control
capacity, the reduction is slightly lower for the Altera 8K part.
As we see in Table , we ultimately expect devices to be wire
or switch limited. In the wire limited case, we may have free area under
long routing channels for memory cells. In fact, dense encoding of the
configuration space has the negative effect that control signals must be
routed from the configuration memory cells to the switching points. The
closer we try to squeeze the bit stream encoding to its minimum, the less
locality we have available between configuration bits and controlled
switches. In Figure
, for instance, we had to run
additional control lines into the crossbar to control the crosspoints.
These control lines compete with network wiring, exacerbating the routing
problems on a wire dominated layout.
In a multiple context or switched interconnect case, the effects of memory density are more pronounced. Limited wire resources are reused in time, making more efficient use of the wires and minimizing the effects of bisection wiring limitations. In these cases the chip needs to hold many configurations worth of memory simultaneously. If one is not careful about the density of the interconnect configuration encoding, the configuration memory stores can dominate chip area.
In the aforementioned DPGA Prototype [TEC +95a], for example, even with four on-chip contexts, wiring and switching accounted for over half of the die area. Network configuration memory made up about one fourth of the area. A factor of 2-4 increase in the configuration memory due to sparser encoding would have forced a substantial (20-60%) increase in die area.
Of course, the real problem associated with reconfiguration time is the i/o bandwidth limitation. It is certainly not necessary for the bits stored in the configuration memories to be identical to the off-chip interconnect specification or the specification transmitted across the chip boundary. In wire limited cases, where local memory cells are inexpensive or free and routing control signals are expensive, the device could decompress the configuration specification during configuration reload time.
For example, let us revisit the LUT interconnection example from
Section in the wire limited case. Here, we
suppose the technology costs dictate that the memory-cell-per-crosspoint
design is more area efficient than the denser encoding schemes identified
that section. We could build a single copy of the decoder for the
bit encoding
scheme. This single decoder could then be used to decode each 11 bits of
LUT input configuration into the 60 bits required to program the input
crossbar. As a result, we reduce the LUT input portion of the bitstream by
a factor of
over the unencoded case.
It is worthwhile to note at this point that the compression we are discussing here is design independent. That is, the bounds on configuration size we have derived throughout this paper are applicable across all possible interconnection patterns which a network may provide. It is also possible to exploit redundancy within the design to further compress the configuration bit stream in a design dependent manner.
Sparse interconnect configuration encodings can result in bloated bit stream configurations. Asymptotic growth rates suggest that dense encodings grow more slowly than desired interconnect requirements, placing designs in a wire and switch limited domain. Consequently, some encoding density may be judiciously sacrificed at the on-chip storage level to decrease control interconnect in programmable devices. Multiple-context components, on the other hand, have a greater demand for on-chip storage and merit denser encoding in order to make effective use of silicon area.
Sparsely encoded bit streams have their largest impact on configuration load time. As device size increases and the reconfigurable aspects of programmable devices are heavily exploited, the i/o bandwidth limited reconfiguration time becomes a significant performance factor. Dense configuration encoding can be exploited to minimize the external storage space required for configurations and the transmission time required to communicate configurations.
At a broader level, we have focussed on interconnect flexibility to establish gross bounds on the information required to configure a device. We demonstrated simple building blocks and metrics for gauging the flexibility of an interconnect and apprising the level of redundancy in a particular interconnect description. These tools can be useful for first order analysis of programmable interconnect designs.
Dense encodings can make a single switch depend on many configuration
bits. In Section we pointed out that decoding time affects
performance, in multicontext designs. In the DPGA LUT input case introduced
in Section
, full encoding to achieve 11 bits
requires that we look at all 11 bits to set at least one of the input
sources, making for moderately slow encoding.
To keep decoding time low, we might impose the additional constraint
that each input have an independent set of bits controlling its source
selection. In the full crossbar input case, for example, we had 4 bits
selecting each input source. The question then, is: Can we exploit the
input equivalence classes imposed by the -LUT to achieve a tighter
result while retaining independent input decoding?
We can, in fact, achieve a better encoding within these constraints. For
any choose
, case we can build a structure with only
crosspoints, requiring
bits. In the case at
hand (
,
), that means we need only 48 crosspoints while still
requiring 16 control bits. Alternately, it means we can supported as many
as 19 input sources with the same 16 control bits and only 64 crosspoints.
To achieve this bound, we organize the inputs as follows:

That is, the first input gets sources , the next
, and so on. The final input gets sources
.
Proof: Any set of inputs must contain one of the sources assigned to
input 0 (
). There are only 3 other sources left, so
if we need four inputs, one of them will come from this set. Now, we have
two cases:
Given the constraints of separate input selection, it is not possible to get away with any fewer crosspoints and still retain full connectivity.
Proof: Each of the LUT inputs must be able to select at least one
of the needed input values. If any of the inputs can select
from less than
values, then one could pick a set of
values
which were not in said input's set of choices. Since this input cannot
provide any of the selected inputs, the selected input pattern cannot be
routed. Therefore, the
inputs would not be able to select all
subsets of size
, as desired.
This arrangement is optimal since it is both complete and minimal.