METRO: A Router Architecture for High-Performance, Short-Haul Routing Networks
Andre DeHon,
Frederic Chong, Matthew Becker, Eran Egozy,
Henry Minsky, Samuel Peretz, and Thomas F. Knight, Jr.
Original Issue: October, 1993
Last Updated: Wed Nov 3 20:00:13 EST 1993

The METRO architecture is optimized for low-latency, fault-tolerant node-to-node communications in tightly-coupled computing environments such as high-performance multiprocessors and network routing hubs. The basic routing function employed is simple yet powerful. Simplicity is achieved by pushing the responsibility for message buffering, congestion handling and fault handling outside of the network. The simplicity of function in METRO is analogous to contemporary trends in processor design: Functional complexity is reduced to speed primitive operation. While each router's behavior is simple, an assembled network behaves in a sophisticated manner, requiring little assistance from the source node to efficiently handle most cases of congestion control and fault avoidance. The METRO architecture is defined in a general manner which separates the fundamental characteristics of the architecture from implementation parameters. Freedom in choosing implementation parameters provides flexibility to customize particular METRO implementations to suit target applications and available technologies. Combining simple routing with freedom to optimize to the target technology, METRO implementations can achieve very high-performance supporting both low-latency and high-bandwidth communications.
Each METRO router is organized as a dilated crossbar routing component supporting half-duplex bidirectional, pipelined, circuit-switch connections. METRO routers may serve as the principal building blocks for a wide range of indirect, multistage routing networks. METRO routers feature:
Section describes the communications domain where METRO is
most suitable. In Sections
through
we review the terminology used in describing routing
components and describes the basic operation and architecture of METRO
routing components. Section
describes sample implementations of
the METRO architecture. Section
reviews several
contemporary routing networks and switches for comparison with METRO. In
Section
, we review the key benefits of the METRO
architecture.
In many applications, including general-purpose MIMD multiprocessing, cross
network latency is the critical factor limiting application performance.
In applications where we can only extract limited parallelism, cross
network latency acts to limit the speedup achievable using parallel
processing. In particular, an application with operations which may
proceed in parallel on each cycle, running on a machine with latency
can, on average, execute
operations per cycle. Only in
cases where parallelism is much larger than the number of nodes (
)
employed to speedup the application (
), is application
performance decoupled from network latency. In cases where application
parallelism is limited compared to the number of available processors, the
achievable speedup due to parallel processing is directly limited by cross
network latency.
We refer to METRO as a building block for short-haul networks to distinguish it from the networking technologies in common use for Local- and Wide-Area Networking (LAN/WAN). LAN/WAN technologies allow the construction of long-haul networks for interconnecting loosely coupled nodes. Long-haul networks are generally used to link together computers in distributed computing environments.
The interconnection distances between computers or routing hubs in long-haul networks are necessarily large due to the physical separation of machines. In these cases, the latency between nodes is dominated by the latency traversing the physical interconnect between nodes. This has two effects: (1) the relative importance of low-latency switching is small since the node-to-node travel time is dominated by the latency required to traverse the long, physical interconnection media; (2) since the time required to inject an entire message into the network can be small compared to the time required to deliver it, interconnection bandwidth is utilized most efficiently by packet switching where an interconnection channel is allocated to a message for only long enough for the message to be injected into the interconnect. Consequently, long-haul networks employ packet switching and are not significantly impacted by the delay through switching elements.
In tightly-coupled networks, the interconnection delays are much smaller and routing latency has a much larger proportional impact on end-to-end message latency. METRO is optimized for these configurations and applications where low end-to-end message latency is critical. In these tightly-coupled situations, the time required to inject a message is often large compared to the end-to-end interconnect latency. We use the term short-haul networking to denote network technologies optimized for the case where end-to-end interconnection latency is comparable to or smaller than the message injection time.
Since message injection time dominates interconnect transit latency in short-haul networks, there is little negative impact on usable network bandwidth if we dedicate resources to a single message for the duration of its communication. Consequently, we can employ circuit switching interconnect techniques without sacrificing significant performance. In these short-haul network environments circuit switching offers several advantages:
Note that these two classes of networking technologies optimize for bandwidth utilization and latency differently based on their domains of application. There is clearly a region of operation between the extremes of short- and long-haul networking. In this region there is a tradeoff between usable bandwidth and end-to-end latency. The choice of an optimization target in this region is often application dependent.
A collection of METRO routers is typically used to construct a
multipath, multistage network. Multiple stages allow the routers to route
data between a source and a destination through a logarithmic number of
routing components. In a multibutterfly-style network, each stage in the
routing network subdivides the set of possible destinations into a number
of distinct classes determined by the radix of the routing components.
Successive stages recursively subdivide the destination class until each
output node from the network is uniquely identified. Dilated routing
components give rise to multiple independent paths through the network.
The multiple paths in the network increase available bandwidth, decrease
congestion, and provide tolerance to link and router faults.
Figure shows a small network of this
genre.
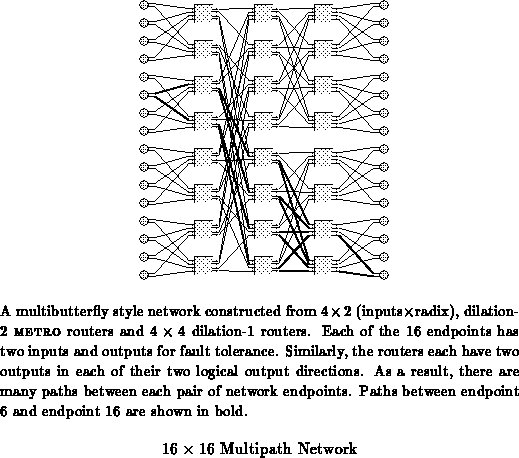
[LM89] and [Upf89] present some of the basic theory on multibutterflies, a well-understood example of multipath networks. Network construction, utilization, and performance issues are further explored in [DKM91] [LLM90] [CED92] [CK92]. Fat-Tree networks [Lei85] [GL85] are another class of multistage, multipath networks which can be built using METRO routing components. [DeH91] details issues involved in constructing such networks.
A METRO router is a dilated crossbar routing component which supports half-duplex bidirectional, pipelined, circuit-switched connections. Each METRO router is self-routing and supports dynamic message traffic. METRO works in conjunction with a source-responsible network interface to achieve reliable end-to-end data transmission in the presence of heavy network congestion and dynamic faults. Fault-localization and reconfiguration capabilities provided through the scan interface allow the router to perform efficiently in the presence of static faults.
A crossbar has a set of inputs and a set of
outputs and can
connect any of the inputs to any of the outputs with the restriction that
only one input can be connected to each output at any point in time. A
dilated crossbar has groups of outputs which are considered
equivalent. We refer to the number of outputs which are equivalent in a
particular logical direction as the crossbar's dilation,
. We
refer to the number of logically distinct outputs which the crossbar can
switch among as its radix,
.
A circuit-switched routing component establishes connections between its input and output ports and forwards the data between inputs and outputs in a deterministic amount of time. Notably, there is no storage of the transmitted data inside the routing component. In a network of circuit-switched routing components, a path from the source to the destination is locked down during the connection: the resources along the established path are not available for other connections during the time the connection is established. In a pipelined, circuit-switched routing component, all the routing components in a network run synchronously from a central clock and data takes a small, constant number of clock cycles to pass through each routing component.
A crossbar is said to be self routing if it can establish connections through itself based on signalling on its input channels. That is, rather than some external entity setting the crosspoint configuration, the router configures itself in response to requests which arrive via the input channels. A router is said to handle dynamic message traffic when it can open and close connections as messages arrive independently from one another at the input ports.
When connections are requested through a METRO router, there is no
guarantee that the connections can be made. As long as the dilation of the
router is smaller than the number of input channels into a router (
i.e. ), it is possible that more connections will want to connect
in a given logical direction than there are logically equivalent outputs.
When this happens, some of the connections must be denied. When a
connection request is rejected for this reason, it is said to be
blocked. The data from a blocked connection is discarded and the source
is informed that the connection was not established.
Once a connection is established through a METRO router, it can be turned. That is, the direction of data transmission can be reversed so that data flows from the original destination to the original source. This capability is useful for providing rapid replies between two nodes and is important in effecting reliable communications. METRO provides half-duplex, bidirectional data transmission since it can send data in both directions, but only in one direction at a time.
Since connections can be turned around and data may flow in either
direction through the crossbar router, it can be confusing to distinguish
input and output ports since any port can serve as either an input or an
output. Instead, we will consider a set of forward ports and a set
of backward ports. A forward port initiates a route and is initially
an input port while a backward port is initially an output port. The basic
topology for a crossbar router assumed throughout this paper is shown in
Figure .
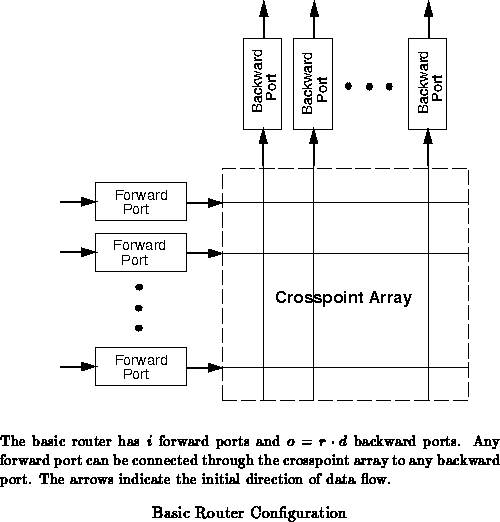
In operation, a network endpoint will feed a data stream of an arbitrary number of words into the network at the rate of one word per clock cycle. The first few data words are treated as a routing specification and are used for path selection. Subsequent words are pipelined through the connection, if any, opened in response to the leading words. When the data stream ends, the endpoint may signal a request for the open connection to be reversed or dropped. When each router receives a reversal request from the sender, the router returns status and checksum information about the open connection to the source node. Once all routers in the path are reversed, data may flow back from the destination to the source. The connection may be reversed as many times as the source and destination desire before being closed. End-to-end checksums and acknowledgments ensure that data arrives intact at the destination endpoint. When a connection is blocked due to contention or a data stream is corrupted, the source endpoint retries the connection.
When a connection is opened through a router, there may or may not be outputs available in the desired logical output direction. If there is no available output, the router discards the remaining bits associated with the data stream. When the connection is later turned, the router STATUS word returned by the routing node informs the source that the message was blocked at the router. When exactly one output in the desired direction is available, the router switches the connection through that output. When multiple paths are available, the router switches the data to a logically appropriate backward port selected randomly from those available.
This random path selection is the key to making the protocol robust against dynamic faults while avoiding the need for centralized information about the network state and keeping the routing protocol simple. When faults or congested regions develop in the network, the source detects the occurrence of a failed or damaged connection by monitoring the router status and the acknowledgment, if any, from the destination. The source then knows to resend the data. Since the routing components select randomly among equivalent outputs at each stage, it is highly likely that the retry connection will take an alternate path through the network, avoiding the newly exposed fault or hot spot. Source-responsible retry coupled with randomization in path selection guarantees that the source can eventually find an uncongested, fault-free path through the network, provided one exists. The number of retries required, in practice, is small. The random selection also frees the source from knowing the actual details of the redundant paths provided by dilated components in the network. Random selection among equivalent available outputs is an extremely simple selection criterion to implement in silicon and can be implemented with little area and considerable speed. Random selection also requires no state information not already contained on the individual routing component.
The METRO architecture contains many features which provide for flexible implementation and application. This section describes many of the key features including:
In many dilated network configurations, it is desirable to utilize
routers with differing dilations in some stages of the network. For
instance, in the network shown in
Figure , the final stage uses dilation-1
METRO routers while the earlier stages use dilation-2 routers. The
dilation-1 routers in the final stage allow the network shown to tolerate
the complete loss of any router in the final stage without isolating any
endpoints from the network. The dilation-2 routers in the earlier network
stages give the network its multipath nature allowing the network to
tolerate congestion and faults in the earlier network stages. To
facilitate this kind of network construction from a single router
implementation, the effective dilation of a METRO router may be
configured to any power of two up to the implementation specified limit,
.
There are several cases in system use or in basic router behavior where it is necessary to keep a connection open while no data is available for transmission. DATA-IDLE is a word passed through the router just like data but which is outside of the normal band of data word encodings. There are two major uses of this designated token:
After opening a connection through a series of routers, the source will generally want a reply back from the destination to verify that the message was received. Often the source will also want to get a response to the connection request. By sending a designated control word, TURN, the established path is reversed in a pipelined manner so that data can return from the original destination back to the original source. During the pipeline delays associated with reversing the connection, each routing component has the opportunity to inject information into the return data stream about the status of the connection and the integrity of the data transmitted; this information is useful to the source in identifying and localizing errors. This path reversal allows METRO to implement efficient, low-latency, request-reply operations such as distributed-memory read operations. Once the connection is established and the request is transmitted, the reply data can stream back along the path opened by the request without incurring any additional latency to acquire a new connection through the network.
To allow arbitrary protocols to be layered on top of the basic METRO router protocol, connections may be turned back to the forward direction. Any number of data transmission reversals may occur during a single connection. It is always the prerogative of the transmitting end of the connection to signal a connection reversal.
If we can clock data between routing components faster than we can route data through a routing component, we can often achieve higher bandwidth by allowing the data to take multiple clock cycles to traverse the routing component. The only place where pipelining affects the routing protocol is when connections are reversed. Following a TURN the number of delay cycles before return data is available will depend on the number of pipeline stages through the routing switch since it is necessary to flush the router's pipeline in the forward direction, then fill it in the reverse direction before reverse data can be forwarded. DATA-IDLE words serve to hold the connection open during the pipeline delays.
The longest latency operation inside a routing component is often connection establishment when arbitration must occur for a backward port. If we require that the connection setup occur in the same amount of time, or the same number of pipeline cycles, as the following data is routed through the component, the latency associated with connection setup will be passed along to become the latency associated with data transfer through the router. Alternately, we can allow more time, generally more pipeline cycles, for connection setup than for data transmission. When we allow this, each router will consume a number of words equal to the difference between the setup pipeline latency and the transmission pipeline latency from the head of each data stream. When constructing the route header, we pad the header to account for the words which each router strips from the head of the data stream during connection setup.
For example, consider a router which can route data along an established path in a single cycle, but requires three cycles to establish a new connection. The router would consume the first two words from the head of each routing stream before it was able to establish a connection and forward the remainder of the data out the allocated backward port.
For long interconnect, METRO routers pipeline data across the wires interconnecting routers. In some network systems, it is generally not possible or desirable to make all the connections between routers equally long. In particular, closer routers should be able to take advantage of the fact that interchip signalling may occur faster ( i.e. less pipeline delays between routers). Since each port on a single router connects to a different router it may be the case that the length of the wires connected to each port differ. For this reason, METRO provides the ability to define the number of pipeline stages associated with each port connection separately. During the time the router is waiting for a response from the turn by the attached routing component, the waiting router will send DATA-IDLE words to hold the connection open until it has reverse data to forward.
One important assumption made here is that we can model the wire between two components as a number of pipeline registers. How one assures that this assumption is satisfied is implementation dependent. With a properly series-terminated point-to-point connection between routers, we do not have to worry about reflections and settling time on the wire. The wire will look, for the most part, like a time-delay. The necessary trick is to make the time-delay approximate an integral number of clock cycles so that it does look like a number of pipeline registers. A brute force way to achieve this is to carefully control the length and electrical characteristics of the wires between components. Another method is to use adjustable delay in the pad drivers themselves to adjust the chip-to-chip delay sufficiently to meet the assumption. See Chapter 6 of [DeH93] for further discussion on suitable delay adjustment technologies.
When a router is unable to route a connection due to the lack of availability of an appropriate backward port, the connection is blocked. There are two ways which a METRO router can handle this situation. The router could wait for a path reversal request and shut the connection down after returning information to the source about the blocked state of the connection. Alternately, the router could immediately begin propagation of a backward drop request back to the source using a designated backward control bit ( BCB). The earlier behavior provides the source with sufficient information to determine at exactly which router the blocking occurred and whether or not any errors occurred prior to that point. The latter behavior releases the resources held by the blocked connection rapidly while only informing the source of the routing stage in which the blocking occurred.
METRO routers allows each forward port to independently select between these two modes. The tradeoff between fast path reclamation and detailed information gathering can be handled dynamically while the router is in use. Note that the mode of path reclamation is solely determined by the configuration of the forward port on the router at which the blocking occurred. If we were to disable fast path reclamation on a single router in the network, only those connections which block at that particular router would hold the connection for a detailed reply. Connections which blocked before or after the router would recover using the fast path reclamation. This allows the system to select portions of the network ( e.g. a particular stage in the routing network or a particular routing component) for gathering detailed information while blocking in the remainder of the network is signalled via fast reclamation for efficiency.
METRO integrates extensive scan support using an IEEE 1149-1.1990 [Com90] compliant Test Access Port (TAP) extended to support multiple TAPs on each component (MultiTAP) [DeH92]. The multiTAP support allows METRO increased tolerance to faults in the scan paths. The TAPs provide a convenient mechanism for setting mostly static configuration options.
In addition to the normal boundary-scan facilities associated with an IEEE 1149 TAP, METRO provides fine-grain facilities for on-line fault-diagnosis. In particular, many of the system in which an METRO router might be used are large and it would be inconvenient or impractical to bring the entire machine down to run traditional boundary-scan style diagnostics. For this reason, METRO routers allow each port to be treated separately for purposes of testing and reconfiguration. Each port can be disabled, removing it from the set of resources in use by the system. The topology and redundancy provided by typical METRO networks allow the network to continue functioning with some resources disabled. Once a port is disabled, boundary and internal scan tests can be applied exclusively to the disabled port or ports while the rest of the router functions normally. This allows a forward-backward port pair, a routing component, or some region of a network, to be isolated from normal operation for testing. Once the fault region is identified, the faulty-region can be left disabled and the rest of the system returned to service. Disabled faults are masked, in that their faulty behavior can no longer corrupt message traffic.
To allow wide routers to be built from routing components with narrow datapaths, METRO provides features to facilitate cascading routers. A router with an effectively wider data path can be achieved by using multiple METRO routers in parallel. Routing components often tend to be pin-limited. Width cascading reduces the competition for pins between datapath width and the number of forward and backward ports supported on a single IC. For any fixed number of IC pins, this allows the IC to support more forward and backward ports without sacrificing network datapath width. For a target logical router size, this allows logical routers to be constructed from primitive router ICs with less pins, and hence less expense.
In width cascading, two or more routers need to behave identically in terms of how they handle connections. METRO provides two hooks to ensure identical connection handling: shared randomness and a wired- AND pull-up.
For shared randomness, the routers receive their random bits from off chip. These bits are used along with the connection requests to decide the assignment of connection requests to backward ports. As long as the connection requests and shared random bits are identical for the set of cascaded routers, the cascaded routers will allocate identically in the non-faulty case. Only in faulty cases should the connection requests, and hence allocations, ever differ.
To handle the faulty case where the routing header is corrupted or a router
behaves abnormally, METRO enforces a simple consistency check on each
backward port. Each backward port has pull-up signal ()
that indicates when the port is not in use. By connecting this signal
across the cascaded routers in a wired- AND configuration, the
backward ports can detect when they disagree about an allocation. Since
any disagreement is necessarily an error, as soon as the disagreement is
noticed, the connection is shut down on all attached routers so that the
fault is contained.
There is still a need for end-to-end checking to assure that messages arrive intact. Though highly improbable, there still exist some cases in which a faulty allocation may go unnoticed by the shared pull-up. The shared pull-up facility significantly limits the negative effects that can be caused by the faults which are most likely to occur.
To avoid the need for additional resources to generate the random bits, the METRO architecture requires each component to generate one random output bit stream. Each METRO router typically has multiple random input bits to support the stochastic path selection.
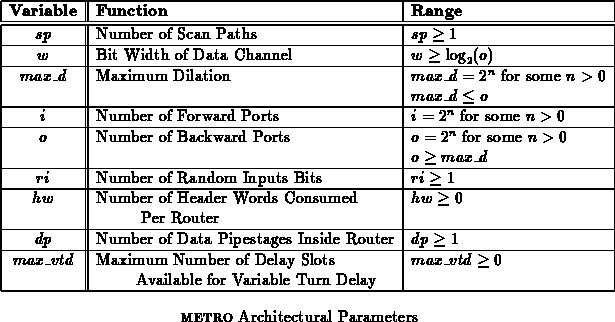
The METRO architecture encompasses a large family of potential router
implementations. All METRO implementations share the same basic function
and protocol. Individual METRO routers may be specialized for
application and implementation technology by the appropriate selection of
architectural parameters. Many of these parameters were introduced in the
previous section. Table summarizes these parameters.
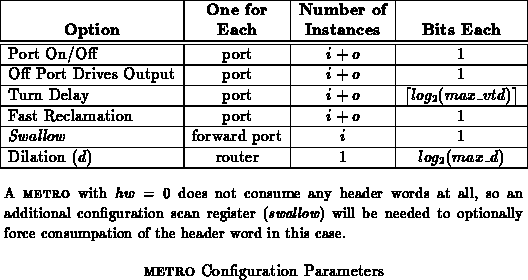
Each METRO router has many options which can be selected each time the
component is used as well as while the component is in use. All of these
options are configurable under scan control from a TAP.
Table summarizes the configurable options available
for any METRO router. Variable turn delay, dilation, and swallow would
typically remain constant throughout operation. Port enables and fast
reclamation may be reconfigured during operation as discussed in
Sections
and
.
RN1, a direct ancestor of the METRO architecture implemented in a
1.2 CMOS process [Min91], ran with an internal latency under
15 ns. RN1 supported 8 forward and backward ports (
), byte wide
datapaths (
) and both dilation-1 and dilation-2 routing. RN1 was
designed so that each routing stage was only a single pipeline stage in the
network. Unlike METRO it did not treat the interconnect as a separate
set of pipeline stages from the internal logic. Consequently, RN1 was
limited to about 50 MHz operation [MDK91].
METROJR is a minimal implementation of the METRO architecture with
,
,
, and
. To date METROJR has been
described entirely in a high-level language and synthesized to a standard
ASIC library using the Synopsys Design Compiler
[Syn92]. Without pipelining connection setup,
the critical path between input and output datapath registers due to
connection allocation contains 25 gate delays.
An initial implementation of METROJR was done through Orbit
Semiconductor under their Encore! program. METROJR was implemented as a
15K gate array in a 1.2 CMOS process. Orbit indicates the components
will run at 40-50 MHz. Running at 40MHz with interconnect accounting for
only a single pipeline stage, METROJR-ORBIT has a 50 ns
router-to-router latency and a 25 ns nibble (4-bit) latency. Since
METROJR supports width cascading, multiple METROJR-ORBIT components
can be cascaded to achieve higher data bandwidth.
Based on the Synopsys results, we are encouraged that a CMOS
standard-cell implementation of METROJR can easily achieve higher
performance. Using a 0.8 effective gate-length CMOS process with 300
to 400 ps gates, we expect a 100 MHz implementation of METROJR can be
realized relying primarily on standard-cell synthesis and layout. Of
course, to support these speeds, custom i/o pads and clocking will be
required to augment the standard-cell logic. Suitable low-voltage swing,
matched-impedance i/o pads have been demonstrated in this process
technology [DKS93] and exhibit sufficiently low
latency and power consumption to make such an implementation feasible.
By taking advantage of connection setup pipelining, even lower data
transfer latency can be achieved without going to a full-custom design.
Simulation of full-custom METROJR implementations indicate that 200 MHz
implementations in the same 0.8 CMOS process are feasible without
connection setup pipelining. By adding a single connection setup pipeline
stage (
), 400-500MHz implementations also look promising.
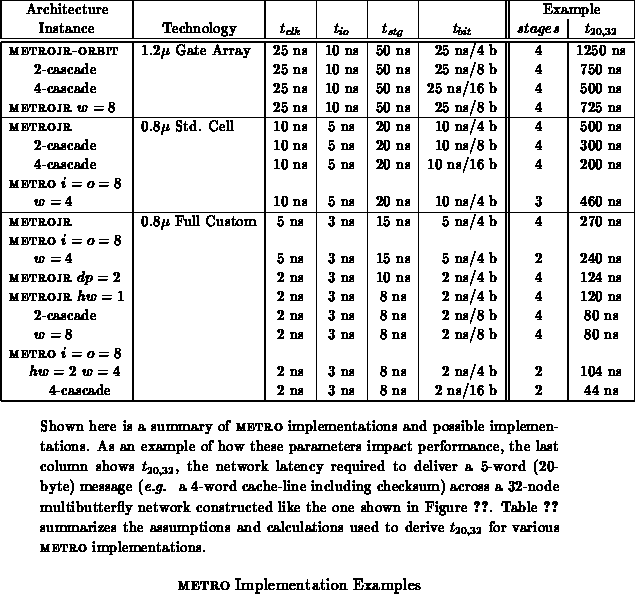
Table summarizes a few potential implementations of
the METRO architecture.

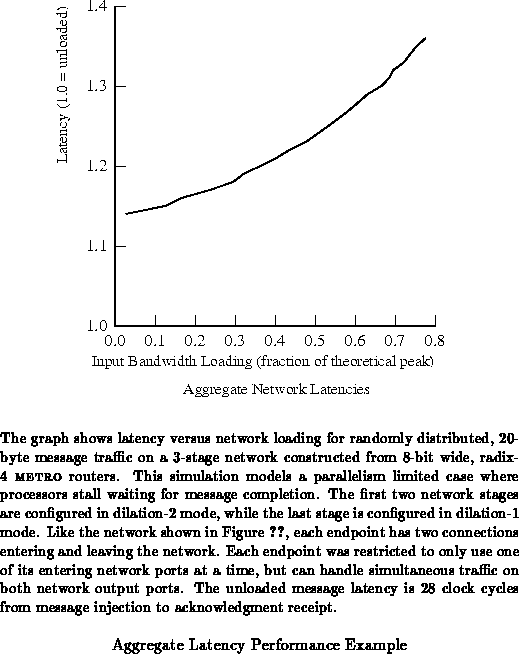
As an example of how loading affects METRO networks,
Figure shows the effective latency of a 3-stage,
multipath network under varying loads. Earlier work based around the
routing protocol which evolved to become the METRO routing protocol shows
that performance degrades robustly in the face of faults
[CED92] [CK92].
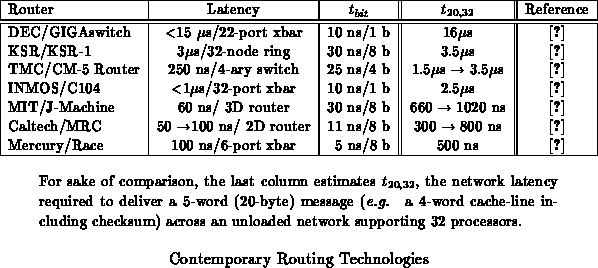
Table shows the performance of several contemporary
routing networks in use for multiprocessor interconnect and network routing
hubs. The DEC GIGAswitch is an FDDI routing hub and is representative of
long-haul networking technologies. The KSR-1 and CM-5 are general-purpose,
commercial, MIMD parallel processors. The MIT J-Machine is an academic
research machine. The Caltech MRC is a full-custom, academic, mesh router
employed by many mesh-based multiprocessors. Mercury/RACE is a commercial
offering for real-time, parallel processing. The INMOS C104 is commercial,
packet-switched crossbar switch intended for use in multiprocessors or
routing hubs. Table
includes an estimate (
)
for the unloaded network latency required deliver a 20-byte message across
the network in a 32-node configuration for comparison with
Table
. As evidenced by the application example,
, even the minimal gate-array implementation of METRO compares
favorably with the existing field of routing technologies.
The ensemble of features provided by the METRO architecture make it suitable for a wide range of applications and allow high-performance implementations both at the single chip level and at the network level.
METRO routers can be implemented to achieve high performance for two key reasons:
Despite the fact that the METRO router is simple, the minimal hooks it does provide allow networks built from METRO routing components to achieve good aggregate performance and fault tolerance. Stochastic path selection allows the ensemble of routers to avoid network congestion and to tolerate even dynamic network faults. Fast path reclamation allows stochastic search for non-faulty, uncongested paths to proceed rapidly. With connection reversal, METRO routing components efficiently support end-to-end protocols which guarantee reliable message delivery.
The METRO architecture describes a large class of routers which can be implemented to serve applications with widely varying requirements. Cleanly parameterized as it is, routers with varying datapath size, input and output ports, and dilations can easily be specialized from the base architecture. METRO allows room for tradeoffs to be made between latency, throughput, i/o pins, and cost on an implementation and application basis.
A fully-synthesized, gate-array, ASIC implementation of the METRO architecture exhibits comparable or superior performance to many, more expensive and more custom implementations of other router architectures. Semi- or full-custom implementations of the METRO architecture hold promise for even higher performance at reasonable costs.