Previous: Empirical Review of General Purpose Computing Architectures in the
Age of MOS VLSI Up: Empirical Review Next: High Diversity on Reconfigurables
In this segment we review hardwired, programmable, and configurable
multiply implementations. The custom multiplier implementations show us
the functional density achievable by custom hardware on its intended task
for comparison with the general-purpose structures reviewed in Chapter .
We use the multiply operation for this comparison because it is relatively simple and important to many computing tasks including signal processing. Because of its importance and regularity, it has received much attention over the years including many, high quality, custom implementations. Multiply is probably one of the first computational operators to be implemented in most new VLSI processes. Considering the amount of attention given to custom multiply implementations, the comparison between custom multiplies and configurable implementations represents an upper bound on the performance disparity between custom and configurable implementations. Few functions, if any, should show a larger disparity, and most show a significantly smaller disparity. Multiply is also interesting since it is the first piece of custom logic added to ``general-purpose'' processors.
In this section we use a domain specific metric for functional
capacity, the multiply bit operation (). To allow us
to compare multiplies of various sizes, we assume each
multiply requires
. As such, we metric
multiply functional density in
and
compute it as shown in Equation
.
An multiply can be done in less than
operations
(see for example [Knu81]), but, for the multiplies reviewed
here, all of the circuits and algorithms do scale as
.
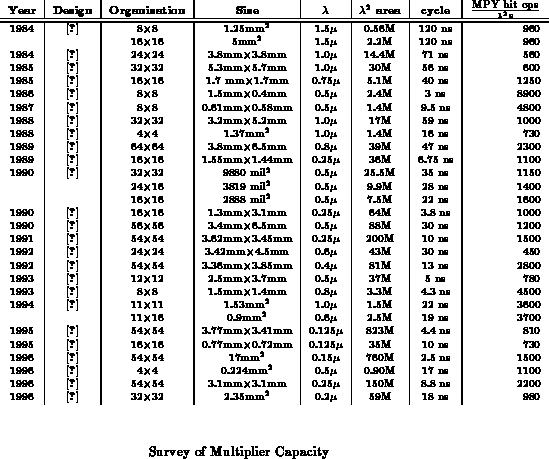
Table summarizes the performance of numerous
custom multipliers according to Equation
.
Implementations range from sub 1000 to almost 9000
with 2000-4000
representing the range of typical,
high-performance, custom multipliers. Like processors there is no clear
trend for improvement with time or decreasing feature size. The latest
designs, if anything, show a tendency to emphasize latency over throughput
resulting in lower functional density.

Table shows a few, sample, semicustom
multiplier implementations. At 330 and 560
, the gate array and standard cell
implementations provide a factor of 5-10 less functional density than the
custom implementations.
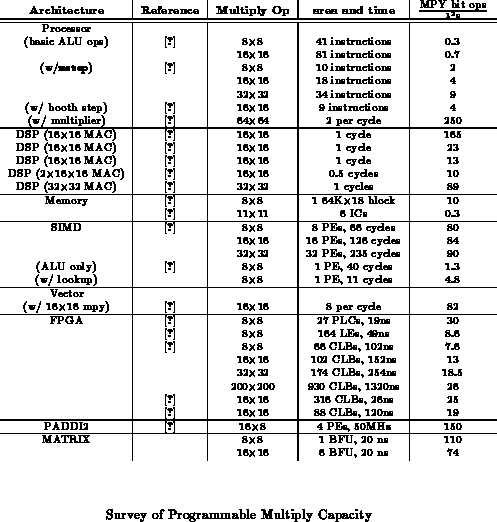

For comparison, Table summarizes
the capacity density of several configurable and programmable
implementations. Processors without specialized multiply support show a
factor of 10,000
lower performance density than hardwired
multipliers. Processors, with multiply or booth step operations have only a
factor of 1,000
lower performance density. FPGAs are a
factor of 100-300
less dense than custom hardware.
Processors, DSPs, and reconfigurable ALUs with integrated multipliers are
only a factor of 10-20
lower in performance density.
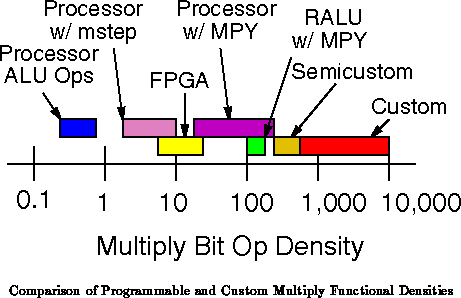
Figure
shows these basic relationships.
One thing we note from Table is
that processors with integrated multipliers provide roughly 10% of
the performance density of a custom multiplier. This comes about simply by
dedicating
10% of the processor real-estate to hold a custom
multiplier. Because of the importance of the multiply function in many
applications and the 100-1,000
performance density differential
achievable by setting aside this 10%, many processors and all DSPs augment
the general-purpose core with a hardwired multiplier. Custom multiply and
floating-point logic are the two main piece of custom logic which have been
regularly integrated onto conventional ``general-purpose'' computing
devices for this reason.
A custom multiplier is often called upon to perform multiplies for a
variety of data sizes. When multiplying operands smaller than the native
multiply size, the custom multiplier yields lower multiply functional
density than indicated in Table .
Table
compares the yielded capacity of the various
custom and programmable multipliers reviewed above.
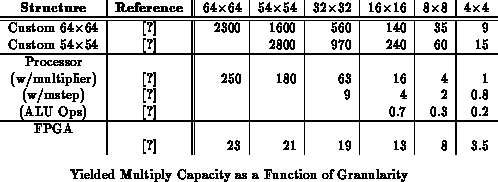

In many applications, one of the operands in the multiply is a
constant -- or changing slowly. In these case, the operation complexity is
slightly reduced, in general, and may be greatly reduce in particular
circumstances. Hardwired, 2-operand, multipliers cannot take advantage of
this reduced complexity whereas programmable and configurable devices can.
Table summarizes the multiply capacity
provided on specialized multiplies. For comparison with the previous
tables, the multiply capacity density is calculated as if it is performing
a full
multiply. It might be more accurate to say the
complexity of the problem decreased rather than the density of multiply bit
ops increased, but the ratio of the performance density numbers is the same
whichever way we view it. Note that the densities shown in
Table
apply for any constant operand.
Particular operands may admit to much tighter implementations.
In general, reconfigurable devices achieve 100-300 lower
capacity density than their custom multiply counterparts. At the same
time, they achieve 10-30
better performance than a processor
building a multiply out of ALU operations. For this particular operation,
most processors include a specialized multiply-step operation, which brings
them closer to parity with the reconfigurable devices, or integrate a
custom multiplier, which gives them a 10
advantage over the
reconfigurable devices. Reconfigurable devices which also include custom
multiply support achieve about the same multiply density as processor with
integrated, custom, multipliers. When large, custom multiplier arrays are
used on small data, the gap between the custom devices and the
reconfigurable devices narrows. Similarly, when a multiply operand is
constant or slowly changing, reconfigurable devices may exploit the
reduction in operation complexity to narrow the density gap.