DPGA-Coupled Microprocessors:
Commodity ICs for the Early 21st Century
Andre DeHon
Original Issue: January, 1994
Last Updated: Sat Jan 29 19:04:40 EST 1994
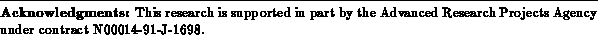
Continuing advances in semiconductor processing have allowed the integration of increasing functionality into single-chip microprocessors. Today's high-performance microprocessors sport 2-3 million transistors and include multiple functional units and large on-chip memories. Microprocessors built for low-cost and embedded systems heavily integrate peripheral control to reduce the chip count for complete systems.
As technology continues to advance, room remains to enhance performance with additional, fixed functional units and reduce costs by integrating more of the computing system onto the microprocessor IC. Nonetheless, simply adding fixed functional capacity will not produce the highest performance on the broadest class of applications nor allow the construction of the broadest range of low-cost systems. Much of the economy in the use and production of microprocessors has come from their commoditization. Integration of fixed functional capacity risks overspecialization and reduced volume utilization per design investment.
For broader application, future microprocessors should dedicate a portion of their silicon real-estate to reconfigurable logic. The reconfigurable logic can be specialized in application-specific ways to provide application acceleration and in system-specific ways to serve as support logic implementing system-specific functions. A single reconfigurable microprocessor design can serve as the principal building block for a wide range of applications including personal computers, embedded systems, application-specific computers, and general- and special-purpose multiprocessors. The wide field of application for the reconfigurable microprocessor allow it to draw heavily on economies of scale and volume production.
In this paper, we look at the technology push (Section )
and application pull (Section
) which argue compellingly for
the tight integration of reconfigurable logic into commodity
microprocessors. We review contemporary efforts to accelerate
application-specific computing tasks (Section
) to
emphasize the range of application where reconfigurable logic has already
proven itself capable of acceleration and to review the typical
shortcomings of contemporary systems. We review the Dynamically
Programmable Gate Array Architecture (DPGA) (Section
) in the
context of microprocessor integrated reconfigurable logic and show that the
DPGA architecture overcomes some of the limitations of contemporary
reconfigurable logic systems. With this background in place, we take a
broader look at the roles DPGA-coupled processors can play in future
computing systems (Section
). Finally, we look at the
acceptance path for this technology (Section
), take a reprise
look at the costs and benefits relative to fixed functional units
(Section
), and look at the challenges ahead
(Section
) before concluding.
Semiconductor processing has continued to improve steadily, allowing the fabrication of smaller and smaller devices. This trend shows little signs of abating. Effective device densities and IC capacity improve at an exponential rate. We are all now quite familiar with the progress of microprocessors where operational performance increases by roughly 60% per year while the number of gates increases by 25% per year. With 3 million gates available for today's modern microprocessors, we can expect to have over 12 million gates available by the end of the century.
As gate densities have improved, more of the computing system has been integrated onto the microprocessor die and larger processors have been implemented. What started as minimal instruction stream control and a simple, 4-bit ALU, has grown with the available area to include multiple, 64-bit functional units including hardwired floating-point support. The basic microprocessor design has expanded to include large, on-chip memories to prevent off-chip i/o latency from significantly degrading performance. Today's high-performance microprocessors move towards higher execution rates using aggressive pipelining and superscalar execution utilizing multiple functional units. Caches increase with instruction throughput in an attempt to prevent off-chip i/o latency from limiting effective computational throughput. Today's cost-conscious microprocessors move to integrate common system and peripheral functions onto the IC die to reduce system cost and power consumption.
Just during the past 6-8 years, we have seen reconfigurable logic emerge as a commodity technology comparable to memories and microprocessors. Like memories, reconfigurable logic arrays rapidly adapt to new technology since the design consists of an array of simple structures. Also like memory, the regularity allows designers to focus their time on adapting the key logic structures to extract highest performance from the available technology. Each reconfigurable array can be designed and tested as a single IC design yet gains volume from the myriad of diverse applications to which the general-purpose array is applied.
Our growing microprocessors can continue their current trends by including more memory, more FPUs, more ALUs, and more system functionality, but it is not clear this will be the most judicious use of the silicon real-estate becoming available in the near future. Addition of fixed functional units will not bring about broad-based acceleration of applications in proportion to the area these fixed units consume. For a given application, the fixed functional units can be arranged to provide almost proportional improvements. However, each application class will require a different selection and arrangement of units to achieve such improvements. Any fixed collection of functional units, control, and data paths will necessarily be suboptimal for most applications.
Improvement in microprocessor performance and system cost can be achieved through specialization and integration. However, such specialization must be balanced against market size to maintain commodity economics. The danger is that overspecialization will reduce the market base and not allow the resulting microprocessors to benefit from commoditization.
The incorporation of reconfigurable array logic into our growing microprocessor provides an alternative growth path which allows application specialization while benefiting from the full effects of commoditization. Like modern reconfigurable logic arrays, a single microprocessor design can be employed in a wide variety of applications. Application acceleration and system adaptation can be achieved by specializing the reconfigurable logic in the target system or application.
Despite ubiquitous use, contemporary microprocessor architectures are poorly matched to most of the applications they run. For almost any application, one can conjecture additions or modifications to prevalent microprocessor architectures which would significantly enhance the application's performance. However, the additions differ from application to application, and there is insufficient commonality among applications to merit inclusion of such additions in a microprocessor with a broad application base. The performance advantage gained by employing specialized coprocessors for high-performance graphics, video processing, signal processing, and networking further demonstrates the performance penalty which accompanies using a general-purpose microprocessor over processors specialized to handle more limited application domains.
Incorporating reconfigurable logic into the general-purpose microprocessor, allows applications to specialize the processing hardware to match the application requirements while allowing a single microprocessor design to maintain its appeal across a broad range of application bases. Special-purpose architectures have long been recognized as one path to higher performance, application-specific computing systems. As we will review in the following section, recent research in the area of customizable computing systems demonstrates that reconfigurable logic can be effectively employed to accelerate many computational tasks. By including reconfigurable logic in the microprocessor, we combine the application-oriented benefits of architecture specialization with the economic benefits of commoditization.
Several research groups have built reconfigurable compute engines to extract high application performance at low costs by specializing the computing engine to the computation task.
Reconfigurable computing engines such as these have been effectively employed in a wide-rage of applications, including:
The applications reviewed here were reported on a widely varying collection of reconfigurable architectures of various sizes. We cannot, fairly, conclude that a single reconfigurable architecture will necessarily exhibit directly comparable performance gains. Nonetheless, the ensemble demonstrates a clear potential for application acceleration via specialized reconfigurable logic across a large range of application.
One theme we see exploited in many of these application is the advantage of exploiting bit-level parallel computation. The reconfigurable array can manipulate a large number of bits in parallel, whereas conventional processor technology focusses on fixed, word-wide data manipulation using word sizes of at most 64 bits in today's microprocessors.
When ALUs are implemented in reconfigurable logic, they can be specialized to perform exactly the function required by the application. This specialization allows the use of more economical functional units both in terms of area and operational speed. This economy can enable the reconfigurable logic to support numerous functional units simultaneously to extract high performance through parallelism.
Another recurring theme is application-specific data flow between functional elements. In a conventional processor it is necessary to spend computational cycles moving data around to match the fixed functional resources and data paths provided. This weakness is often aggravated by limited data-transfer bandwidth within the processing system. In a reconfigurable compute engine, it is possible to customize the data paths between compute elements, as well as the compute elements themselves, to match the application. Rather than juggling intermediate results in and out of registers and memory, the compute engine can be customized so data flows directly from producer to consumer. The specialized data movement is often localized between portions of reconfigurable logic avoiding bandwidth bottlenecks on shared data paths.
Despite the high performance contemporary reconfigurable computing systems provide, they do exhibit a couple of common limitations:
Tight integration of the reconfigurable logic into the base microprocessor can significantly decrease communication latency between the fixed functional units and the reconfigurable logic. Similarly, when the processor and reconfigurable logic share the same die, higher bandwidth is easily available for high throughput processing employing reconfigurable logic. By reducing the communication overhead between the base microprocessor and the reconfigurable logic, we can greatly increase the kinds of application-specific specialization which provide significant acceleration.
The Dynamically Programmable Gate Array (DPGA) architecture [BDK94] is particularly well-suited for reconfigurable computing. Unlike normal Field-Programmable Gate Arrays (FPGAs) where the function of each array element is fixed between relatively slow reconfiguration sequences, the DPGA array elements may switch rapidly among several, pre-programmed configurations. This rapid reconfiguration allows DPGA array elements to be reused in time without significant overhead. Applications can preload multiple, specialized array personalities and switch among configurations rapidly.
Like FPGAs, DPGAs are composed of a tesselation of simple computational
array elements. Each array element can perform a simple logical function
on several input bits producing one or more output bits. Many modern
FPGAs are best modelled as programmable lookup tables. The lookup table
programming constitutes the configuration of each array-element (See
Figure ). Between array elements programmable interconnect
allows the array elements to be linked up as required by the application.
The interconnect in FPGAs is typically configured by programming pass gates
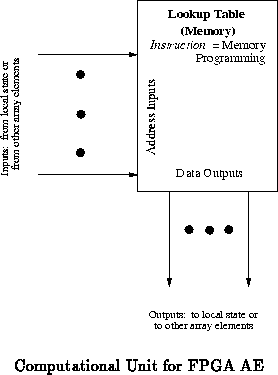
and multiplexors. Each DPGA array-element uses a second lookup table to
map a broadcast configuration selection into a local configuration (See
Figure
). The broadcast configuration behaves like
the broadcast instruction in a SIMD array, telling each array-element which
function to perform on the next clock cycle. Unlike a SIMD array, the
indirection through a pre-programmed, context lookup table allows each DPGA
array element to perform a different function in response to the broadcast
configuration identifier. In a similar manner, the configurable
interconnect in a DPGA array has a table of loaded configurations and
selects between configurations based on the current array context
identifier.
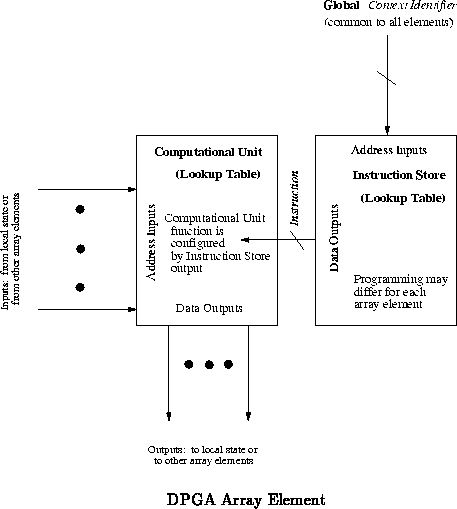
At the cost of somewhat larger array elements and interconnect, the DPGA serves as a multiple-context FPGA. Within the space of preloaded contexts the DPGA can switch personalities completely from one clock cycle to the next. The DPGA configuration lookup table effectively serves as a cache of array element configurations. By giving each array element a small configuration cache, tightly-coupled in the array with the array element, we effectively get very high reconfiguration bandwidth by performing lookups locally at all array elements in parallel. By pipelining the context lookup, DPGA cells need run no slower than comparable complexity FPGA or SIMD logic units.
The multiple loaded context now allow us to utilize the array elements more efficiently. In the most straightforward application, this rapid reconfiguration allows a single DPGA array to be loaded simultaneously with multiple configurations. The DPGA can switch between configurations to accelerate different portions of an application. If the configurable array is too small to hold an entire acceleration logic block, the block can be partitioned across multiple context and evaluated in stages. An application can also make use of the DPGA's capacity to perform computations where the processing elements vary both spatial and temporally. This allows computational functions to be placed where intermediate data resides in the reconfigurable array, taking further advantage of application-specific locality and data flow.
Finally, DPGAs are naturally suited to conventional multitasking or fine-grained multithreading ( e.g. April [ALKK90], *T [NPA92]). In these applications, each thread or context may want to see a different array personality. By partitioning the DPGA contexts and assigning a different context, or sets of contexts, to each thread or task, array reconfiguration will not complicate sharing the processor between tasks or threads.
The DPGA-coupled processor can be efficiently and economically employed as the key computational building block in almost all kinds of computing systems. The computational power and flexibility this component provides will allow it to subsume the role of more traditional microprocessors as well as many processors which have been specialized for application-specific domains. Following is a sampling of DPGA-coupled microprocessor applications:
Integration can evolve smoothly from today's research-oriented,
reconfigurable compute engines to commoditized, DPGA-coupled
microprocessors. Contemporary, reconfigurable compute engines
(Section ) are attached as peripherals to host workstations
and personal computers and serve as a first step in the direction of
processor integrated, reconfigurable logic. The next step will be to
provide reconfigurable logic coprocessors which can be more tightly
integrated with the fixed-logic processor in general-purpose computing
systems. With minor design effort, the reconfigurable logic can be
integrated onto the same die as a core processor. ASIC vendors ( e.g.
LSI Logic, VLSI Technology Inc., Texas Instruments), which provide
core-processors and compiled memories could provide first-generation, FPGA-
or DPGA-coupled microprocessors in the current or upcoming ASIC
technologies with minor up-front design overhead. Native integration of
DPGA arrays into microprocessor designs will require the processor to be
designed with the attached reconfigurable logic in mind. This may entail
additional processor instructions for computational cooperation between the
fixed and reconfigurable logic as well as some rethink of which portions of
the processor should be implemented as hardwired functional resources.
Similarly, the ``programming'' necessary to efficiently employ these machines can evolve towards native integration with conventional compiler technology. The earliest reconfigurable compute engines were configured through explicit, human-crafted gate-designs. Increasingly, the behavior for these reconfigurable computing engines is described at a behavioral level in hardware description languages ( e.g. VHDL, Verilog). In contemporary cases, experts familiar with the reconfigurable architecture develop the configurations for accelerating each application. PRISM [Sil93] and dbC [GM93] demonstrate that conventional programming languages can be restricted or extended to allow programmers more comfortable with programming languages to express computations in a way which can be readily compiled for implementation on reconfigurable logic. For the near future, experts and more sophisticated users can write subroutines for the reconfigurable logic and provide them as library routines. General programmers can make use of the provided library routines for program acceleration simply by accessing them like any other library routine from their high-level programming language. If we make a large library of parameterizable, hardware subroutines known to a profiling compiler, we can employ the compiler to profile applications and select the hardware configurations and library routines which best accelerate each application. The compiler can treat the replacement of sequences of instructions on the processor's fixed logic with known, hardware subroutines as a potential optimization transform and evaluate the relative merits in a manner similar to conventional compiler transforms. Eventually, hardware synthesis technology and conventional compiler technology will converge and the compiler will manage both the reconfigurable and fixed resources on the microprocessor.
We may also see the emergence of hybrid solutions like the Xilinx HardWire Gate Arrays [Xil93]. In systems where the configured logic is employed in a fixed manner, stable designs can migrate from the reconfigurable microprocessor to a microprocessor with an equivalent gate array which can be programmed at the mask level. This provides some of the advantages of fixed, specialized logic by reducing die size while retaining many commodity advantages. The tooling cost is low since few masks are required to personalize the generic design. Further, the specialized logic can follow the hard-wired array through processing advances.
When designing native microprocessors with integrated, configurable logic, we have the opportunity to migrate functionality which has traditionally been implemented as processor fixed logic into reconfigurable logic. In particular, we can consider moving some of the more complicated control structures, especially those dealing with exception handling, into reconfigurable logic. This migration can provide considerable flexibility and a number of practical advantages, including:
The DPGA architecture can mitigate this drawback by providing on-chip, context caches for array configurations and memory for computed intermediate values. However, the number of on-chip contexts each DPGA instance provides is fixed. Sharing reconfigurable resources among a larger number of users or tasks will require provisions for offloading and restoring computations. To further mitigate the expense of unloading and reloading a context, reconfigurable-array savvy compilers can explicitly identify points in the computation where the state inside the reconfigurable array is minimal. By specializing context loading and unloading code to store and retrieve only the necessary state and reconfiguration, the compiler can produce lower overhead code for context swapping.
Microprocessors with tightly-integrated, rapidly reconfigurable logic
promise to be a prime commodity building block for computing systems during
the early part of the next century. We have seen that we can achieve high
application performance by specializing the computational resources to the
application. A microprocessor with integrated reconfigurable logic allows
us to take advantage of application-specific specialization for extracting
high performance while maintaining broad-based, high-volume appeal to reap
the benefits commoditization. Tightly coupled DPGA processing arrays
overcome the primary limitations of contemporary reconfigurable compute
engines by significantly reducing the overheads associated with both
processorarray communications and array reconfiguration.