Notes on Context Distribution
Andre DeHon
Original Issue: February, 1995
Last Updated: Sat Apr 8 21:32:47 EDT 1995

This note briefly describes some basic configurations for context distribution for DPGAs (tn95).
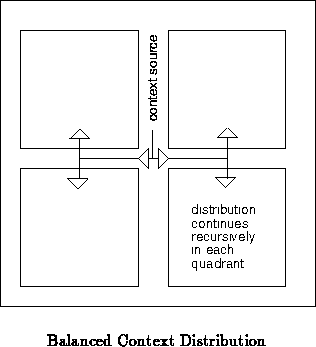
In its simplest form, the context line may come from off-chip and is
buffered and distributed to each array-element (gate) memory and each
interconnect (crossbar, switchbox, etc.) memory. This distribution occurs
in a balanced form ( e.g. balanced H-tree) much like a clock network
(See Figure ).
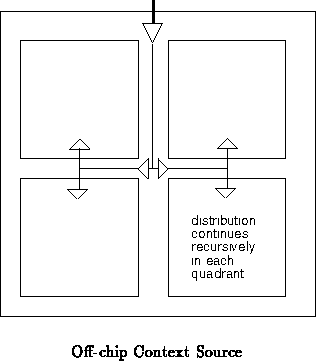
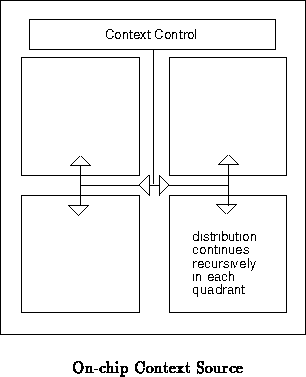
The context source may be on or off chip. In the most minimal case, an
off-chip controller provides the context signal (See
Figure ). The ``context source'' in
Figure
then becomes the i/o buffers which bring the
context specification onto the chip. In a more sophisticated case, the
context source may be a piece of hardwired logic on-chip, an on-chip
sequencer or processor, or even another piece of programmable logic on-chip
(See Figure
).
The context may also be configurable. This configuration would, of course,
either not be context'ed or would be controlled by a different context
signal than the array configurations. Figure
show a generic example of such a configurable context scheme.
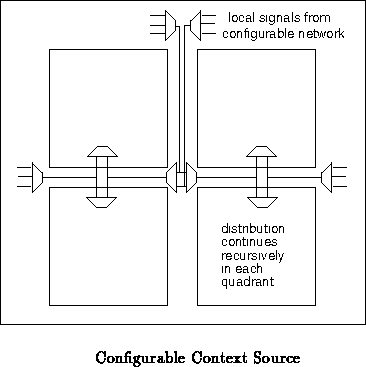
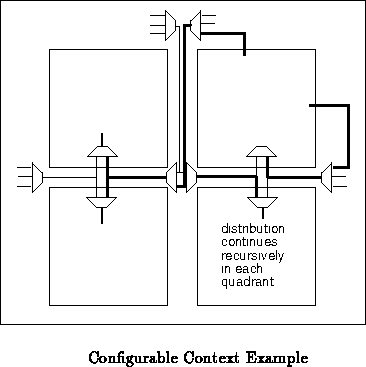
Figure shows a specific configuration on
top of the generic scheme. In the specific configuration the top, right
quadrant is acting as a controller for the rest of the array. The logic in
the top, right quadrant produces the context signal which is eventually
distributed through the configurable context distribution to the rest of
the array. Also shown in the example is that the top quadrant also
controls its own context selection.
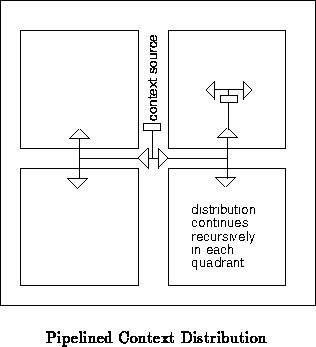
The context distribution may be purely combinational from the context
source or may be pipelined. The context distribution may entail a large
delay, especially when the context source is off-chip. Without pipelining,
the time for context distribution will add to cycle time. By adding
pipeline registers in the distribution path ( e.g.
Figure ), this distribution time need not limit
the clock frequency for array operation. In general, pipeline registers
would generally be added at selective fanout points. e.g. pipeline
registers might be added at every second or fourth fanout buffer point.
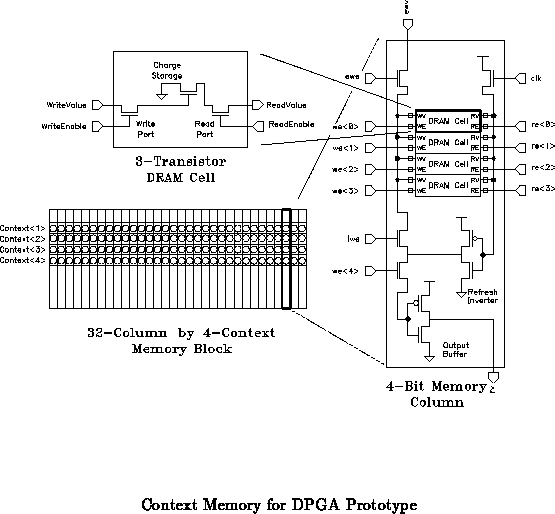
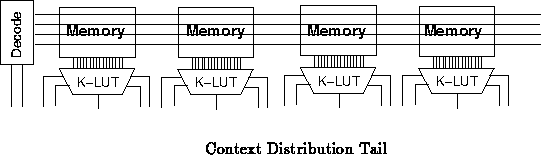
At the tail of the context distribution, it may make sense to distributed
decoded context lines to individual memory arrays. For example, in the
first generation prototype DPGA, we had a single local decoder for each
group of four array elements. As shown in Figure the
two context lines in the prototype were decoded into the four context
select lines which were actually distributed to each memory. Each group of
four crossbar context memories also shared a local decoder in the same
manner.
Pragmatically, there is a balance between distribution bandwidth and
decoder space. We save routing area by distributing fully encoded lines.
However, in the extreme, that would require a decoder for every memory to
decode the encoded lines into memory selects. We save decoder space by
sharing decoder across multiple memory elements. In the extreme here, we
have one decoder and are distributing one line for each context rather than
lines for
contexts. In general, one chooses a point between
these extremes depending on the relative premium for routing channels and
area in the particular design.
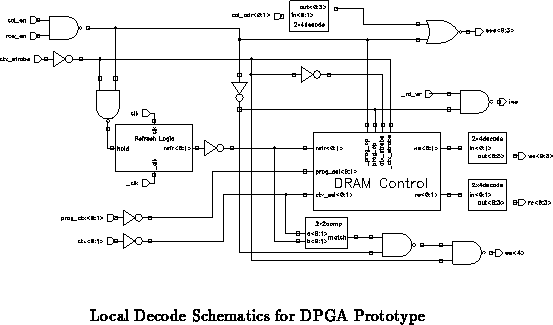
In the DPGA prototype, separate, decoded context read and context write signals
were actually distributed across the memory columns. Figure
is the memory column showing the decoded read and
write lines required by each memory cell. Figure
shows the
local decode schematic for the prototype. This local decode: