Global Perspective
Andre DeHon
Original Issue: May 1990
Last Updated: Tue Nov 9 12:30:49 EST 1993

The MIT Transit Project aims to design, build, program, and utilize novel massively parallel MIMD computer architectures. We utilize cutting edge technology to achieve practical systems with a high degree of both scalar and parallel performance. To make very large computer systems practical, we are concerned with fault-tolerance and scalability.
Many models have been proposed for MIMD parallel computation in recent years. These models include message passing, shared memory, dataflow, and systolic arrays. Many groups have proposed architectures appropriate for their favorite model of parallel computation. We believe that the basic requirements for large scale parallel processing are essentially the same. That is, the resources and hardware will be essentially identical regardless of the computational paradigm used to program the machine. With this belief, we aim to design and construct a massively parallel computer which can efficiently support most of the parallel processing paradigms currently under study. This will allow the programmer the freedom to utilize his favorite model of computation (or the model most appropriate for a particular computation).

Figure shows our high-level view of a parallel computer.
In our effort to synthesize a parallel computer, we have decided to start with the network. Network technology is currently disproportionately behind the other components of parallel computers. As such, we feel it needs the most attention initially.
In all paradigms of parallel computation, network latency is an extremely critical performance factor [Kni89]. As such, low-latency is a primary concern in our design of a high-performance network. Since we intend our designs to be practical and scalable for very large computer systems, fault-tolerance is also a key concern.
To achieve fault-tolerance and low-latency, our network is an unbuffered, circuit switched, multistage routing network with redundant paths. Circuit switching, redundant paths, and random routing allow us to use a source responsible routing protocol to achieve fault-tolerance [DKM90] [Kni89]. The redundant paths decrease the probability of blocking in the network, thus increasing routing performance. Performing unbuffered, oblivious, circuit switched routing makes the routing protocol simple. This simplicity allows us to construct simple and fast routing switches to achieve low-latency connections [Kni89].
Current networks under consideration are configured as banyan or bidelta networks. For small and moderate sized networks, this provides a uniform low-latency connection between all nodes. For very large systems, we are considering fat-tree network configurations which allow us to exploit locality [DeH90a].
For our first pass at a network implementation, we rely on the probabilistic properties of the data and network in order to route a large portion of connections simultaneously utilizing random oblivious routing. We are considering ways to perform adaptive routing in the network [Cho90] (tn1).
As we build very large networks, we will eventually want to make use of packet switching to optimize network throughput. Devising a fault-tolerant, packet switched, routing scheme will be much more difficult than devising the circuit switched routing protocol. However, we eventually hope to find a suitable scheme. We expect the routing switch for a packet switched routing scheme will be more complicated than the current switch. This added complexity will make the task of implementing a fast router more difficult.
We are currently considering the design of a processor optimized for high symbolic and numeric performance in a massively parallel computer. The processor will be implemented in a RISC, pipelined, register machine style. The processor will manipulate 64-bit wide words using the IEEE 754 double-float floating point format [Com85] as the basic data format. The processor will support a tagged architecture for efficient execution of LISP. In the interest of efficient multi-model programming, we intend to provide efficient execution of common declarative languages ( e.g. C, Fortran) as well. The instructions and non-double-float data items will be encoded in the NaN codes of the IEEE double-float format. We aim to achieve rapid context switching and interrupt service by saving the entire processor pipeline on context switches. We hope to achieve a single-cycle context switch. The processor will be superscalar (long instruction word) supporting a generic ALU operations, an address computation, and a load/store operation simultaneously. To support this concurrency, a large, fast multi-ported register file is a necessity.
In modern computers with hierarchal memory running at different speeds, high performance computer system must make an effort to keep the data needed most frequently in the fastest local memory. Additionally, when building parallel computers, effort must be expended to interface with the rest of the computer over the network and maintain coherence protocols. Ideally, we would like to offload these tasks of data movement and coherence to separate control units, thus freeing the processor to simply perform computations.
With the goal of freeing the processor almost exclusively for computation, we are considering a memory coordinator (or coordinators) to perform such functions as:
Inherent in the development of high-performance, massively parallel computers is the utilization and advancement of state of the art technology. We intend to effectively integrate emerging technologies into our designs. Simultaneously, we aim to push technology in areas we need most.
In very high speed digital systems, such as the computers we are designing, packaging is critical. In these systems, wire delays between components can be comparable or greater than logic delays. This makes wire length a critical concern in optimizing system performance. Additionally, in building highly interconnected systems, such as our network, the interconnection bandwidth is extremely high. This further demands dense packaging in order to achieve close physical proximity.
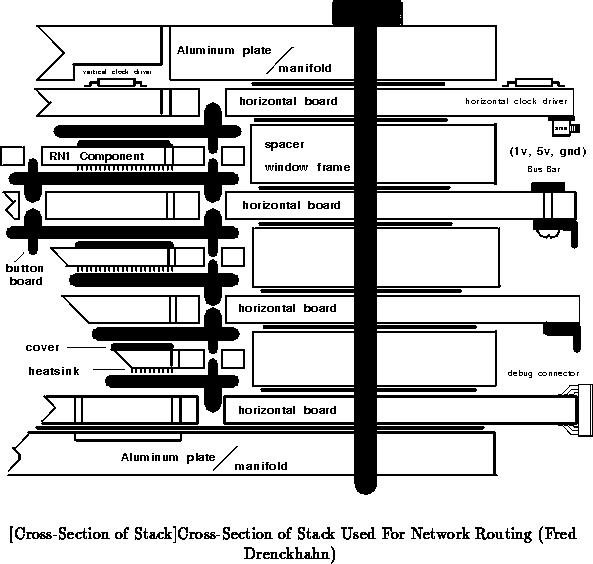
To achieve dense packaging, we are developing true three-dimensional
packaging schemes. Our basic packaging unit is a stack. This is a
cube constructed by sandwiching layers of components between horizontal
pc-board layers. The pc-boards perform inter-stage wiring.
Figure shows a partial cross-section of a stack.
Contact is made between components and the horizontal pc-boards
through button board carriers. These carriers are thin boards, roughly the
same size as the component, with button balls [Smo85] aligned
to each pad on the routing chip. These button balls are 25 micron spun
wire compressed into 20 mil diameter by 40 mil high holes in the button
board connector. They provide multiple points of contact between each
routing component and horizontal board when the stack is compressed
together; in this manner they effect good electrical contact without the
need for solder. This allows ease of packaging construction and component
replacement.
Tightly packing high-performance components requires significant attention to cooling. Channels are provided both in the stack and through each routing component for liquid cooling. FCC-77 Fluorinert will be pumped through these channels to provide efficient heat removal during operation.
Transit packaging is described further in [Kni89].
Chips must be able to communicate with each other at high data rates in order to achieve high performance. External switching costs power as transmission lines must be charged and discharged. On unmatched transmission lines, the digital signal must settle before it can be sampled, incurring further delay for interchip communication. To allow high switching rates, we are developing i/o pads which only swing one-volt. This cuts power consumption by a factor of 25 over five-volt i/o pads and decreases the time required to charge the transmission lines. To avoid reflections on signal lines, we are implementing dynamically matched impedance output drivers. These output drivers measure reflections on the line and dynamically adjust their impedance to match the impedance of the transmission line [KK88] [Kni89].
Component bond wires are one of the major sources of faults in digital systems. In an attempt to obviate this problem, we are considering schemes to capacitively couple the i/o pads to the substrate to which the chip is connected. This will allow data to be communicated off-chip without bond wires.
While our architecture is intended to be very general, many system concerns should be addressed explicitly. Additionally, we have many of our own ideas on how to most efficiently utilize a massively parallel computer.
One can make the observation that the problem of global memory coherence among parallel independent processors, each with its own private cache, is the same problem as data base consistency. The primary difference is that data bases run orders of magnitude slower than reasonable memory systems. We are exploring the extent to which protocols and coherence schemes from the data base world can be utilized to achieve memory coherence in a parallel computer. One prominent issue is the level at which to implement transaction modeled coherence schemes. [Kni86] considers one possible implementation of this kind of coherence.
In order to run LISP, and other heap oriented languages which allow objects to have indefinite lifetimes, on our parallel machine, we must be able to perform garbage collection in parallel. No satisfactory protocols or methods are currently known for efficient parallel garbage collection, in general. We hope to devise and test efficient schemes for garbage collection in parallel systems. We are considering this problem in parallel with our architectural development in hopes of providing a small but sufficient amount of hardware support to allow garbage collection to occur with minimal impact on critical computational resources.
We also hope to explore new languages, and extensions to existing languages, which are both straightforward to use and tractable to compile efficiently.
To utilize our processor and architecture most efficiently, we need smart compilers. With a RISC style processor in a parallel architecture, compiler efficiency is just as critical as raw processor performance. The compiler must effectively schedule operations in each instruction stream and decompose the compiled code into components which can be concurrently executed.
[Kni86] explores the possibility of compiling standard LISP into transaction blocks and optimistically allowing any number of these blocks to be executed in parallel. Errors in the sequencing of operations or blocks are detected dynamically at run-time and code blocks are recomputed as necessary. This allows for optimistic scheduling of all transaction blocks instead of assuming worst-case ordering constraints.
In order to support multiple models of computation we will eventually need compilers and run-time systems for each model of computation.
For a complete computational system, we will need run-time systems to deal with scheduling and resource management.
As mentioned in the previous section, the compiler should be able to break up computations into transaction blocks and efficiently schedule the use of the resources on a single processing node. However, the compiler is unlikely to be able to provide much more than hints about the dynamic behavior of the program executing in parallel on multiple processors. The transaction model allows for the correct execution of programs parallel. This, however, still leaves the issue of scheduling transaction blocks on processors.
One idea for scheduling which we would like to explore further is that of using the network to perform dynamic load balancing (tn2). In fact, extensions of this idea may be worthwhile when allocating memory within a single node.
Application code to simulate and execute on our parallel machines is absolutely essential. This is necessary to evaluate the impact of various architectures and protocols. Unfortunately, since the field is far from maturity, no suitable ``typical programs'' or applications currently exist to simply be used. As we develop our languages and compilers, we must begin to create our own repertoire of applications.
One theme for applications development which we would like to support is that of CAD software. As computer users, as well as, designers, CAD tools are one area of software development we would like to help move into the realm of parallel operation.
The story so far...
RN1 is the routing component we have designed to implement the routing
network described in Section . RN1 is an
crossbar
router with a dilation of 2. Designed in HP's 1.2 micron CMOS process,
RN1 is targeted to run at 100MHz. RN1's i/o pads will be one-volt swing
matched impedance drives as described in Section
[Kni89] [DKM90].
A custom component package and button board connector have been designed for RN1. These are currently being fabricated. The core logic for RN1 is virtually complete and will be sent out for fabrication with standard five-volt i/o pads. The i/o pad design is also close to completion and test pads should be fabricated in the near future. When both of these portions of the RN1 design have been verified independently, we will integrate the low-voltage drivers onto the RN1 core logic and fabricate the complete chip.
Our experience with RN1 has led us to consider many alternatives beyond those implemented in the RN1 design. These will be considered for future version of the routing component (tn1) [DeH90g] [DeH90d] (tn4).
We have developed simple probabilistic models for predicting the
performance of unbuffered switching networks such as the ones we describe
in Section [KS90]. We are trying to extend this work
to derive more sophisticated models which take into account buffering
outside of the network.
We are implementing a fast functional simulator for our network. This will allow us to check the assumptions in our probabilistic modeling and verify the results obtained. This will also be use to test the benefit of suggested alternatives in routing component function. Particularly, this will enable us to consider the value of the proposal presented in [Cho90] (tn1) [DeH90g] [DeH90d] [DeH90f].
We recently began serious consideration of the processor design. We aim to begin processor simulation in the very near future.
Designing and constructing the ideal MIMD computer is too large of a task to undertake all at once. This is especially true since we do not fully understand the problems and issues involved in building an efficient large scale parallel computer. The Modular Bootstrapping Transit Architecture (MBTA) is intended to be a series of intermediate machines which will allow us to study many of the architecture, protocol, and software issues [DeH90b]. Additionally, MBTA will allow us to test our network and packaging in a representative usage. MBTA will provide a platform on which to design and test various architecture models and collect useful statistics. As an emulation platform, MBTA will also allow software to be developed and tested for the proposed architectures.
Detailed MBTA design is currently in progress.