Prospects for a Smart Compiler
Andre DeHon
Ian Eslick, Thomas Knight, John Mallery
Original Issue: June 1993
Last Updated: Sun Apr 24 14:09:38 EDT 1994
We see considerable promise in a truly ``smart'' compiler. By ``smart'' we refer to an adaptive compiler which acquires feedback from the dynamics of program execution and uses this information to tune the compiled code to minimize execution latency. Ultimately, we see the compiler learning the best way to transform and schedule code based on observed run-time behavior.
Such a compiler promises to significantly raise the abstraction level at which compiler writers do compiler development and to automate much of the drudgery associated with developing compiler optimizations. The greatest benefits from such a compiler will be in realm of compilation for parallel and distributed computing where the transform and optimization space is huge and conventional compiler technology is in its infancy. Properly done, such a compiler would be highly portable, even among machines with widely different operation costs, since it is empowered, by design, to adapt to the dynamic behavior of the target machine.
This compiler strategy opens up significant opportunities to tune program performance to users and usage patterns. A user need not pay run-time costs for functions he seldom uses. At the same time, it enables high-level programming to achieve good performance. Since the compiler tunes the code based on dynamic execution frequencies, the compiler should relieve programmers of the need to perform such tuning.
This document is intended to layout the prospects for a ``smart'' compiler and invite discussion on the matter. Your feedback is solicited. Andre DeHon (andre @ai.mit.edu) is currently serving as a central point of contact for feedback.
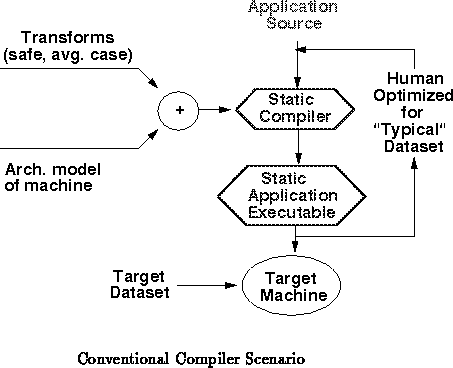
The conventional compilation paradigm has us:
If the performance is unacceptable, the programmer goes back to the source and rewrites the program and/or compiles the program with different compiler options. The clever and performance savvy programmer may run profiling tools to identify where his effort is best spent optimizing the program.
In a similar manner, the compiler author is also writing a program. He writes a program to perform a set of transforms on any source code to produce an executable. He must decide which set of transforms on the source code produce the most efficient executables. Since his input space of programs is huge and often suggest incompatible transforms to produce optimal codes in all cases, he relies on accepted suites of benchmarks to judge the efficiency of his transforms.
The performance of our programs is the result of separate optimization efforts by two groups of human programers -- the application program authors and the compiler authors. Both of these agents analyze expected usage of their products, to the best of ability, and try to optimize for the most efficient (generally, lowest execution latency) programs on what they believe to be the most common datasets.
As a result of this scenario (depecited in Figure ):
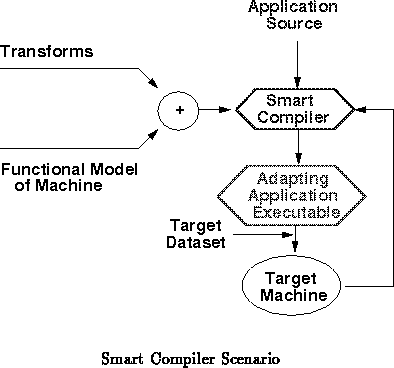
Instead of this conventional view, we envision a compiler which
continually monitors dynamic program execution and tunes and recompiles the
executable code based on this run-time feedback (See
Figure ). Based on the time costs of operations
in the execution environment and on the usage patterns, the program is
recompiled to achieve shorter execution time. The compiler directs a
search among the large space of potential program transforms and
compositions of transforms to identify the most efficient way to execute a
given program on a particular system for a given usage pattern. The
optimization target, minimal execution latency, is well defined.
Throughout a program's lifetime, the compiler can continue to streamline
the program's execution.
Additionally, we envision the compiler keeping track of the programs run, their datasets, and dynamic information from previous runs. In spare machine cycles, the compilation system can rerun the program on the datasets it sees in use. Like its human counterparts, the compiler can focus its optimization attention on program segments in proportion to the frequency they are executed and hence have the most effective impact on execution latency. These ``spare cycle'' compilations effectively take advantage of spare machine throughput to decrease critical execution latency on future program runs.
By allowing the compiler to collect and reason about feedback from run-time dynamics, we empower the compiler to make educated decisions about which transforms are most effective in which settings. The compiler can test out each code transform with the datasets of interest and determine the actual execution times of the transformed code. Dynamic execution data allows the compiler to intelligently restructure the program for minimum latency along the execution paths most frequently used. The compiler, now, takes over the role of deciding which transforms to apply to a source program in order to achieve maximum efficiency. Rather than the compiler and program each being separately optimized for good average case performance across one dataset and remaining static, the compilation transforms and compiled code can fully adapt to the input program and dynamic usage pattern. The end result is higher performance for an end-user's application on the user's machine and the user's dataset.
The compilation system maintains a database of information on the program including information collected from run-time evaluation. The compilation system would also develop and maintain a knowledge base of code transforms and their results. Through time, the compiler would develop a significant database from its experience compiling programs. In effect, the compiler will learn the best ways to compile various code sequences in general, as well as, the best way to compile each application program in specific.
Work on trace scheduling techniques by Joseph Fisher and others first at Yale, then at Multiflow and Hewlett Packard, demonstrates the basic potential for using run-time feedback to generate more efficient compiled code [Fis81] [Ell86] [CNO +88] [FF92]. This line of research has focussed on producing a single, static executable optimized based on control-flow feedback from experimental program runs. Trace scheduling compilers reschedule code to streamline the most common cases based on run-time experience. However, unlike the envisioned smart compiler system, traditional trace scheduling compilers depend on the programmer to provide the reference dataset and compiles a single static executable for a particular architecture and machine configuration. The effectiveness of trace scheduling in this restricted environment, nonetheless, demonstrates the basic validity of using run-time feedback for program optimization.
We seek to go beyond the trace scheduling work in several ways. The smart compiler uses feedback not only on dynamic control flow, but also on dynamic data dependence and data flow as well as operation and communication latencies. We target a much more automated system, where the compiler manages dynamic feedback and program tuning. Compiled code evolves with the dataset in use rather than being fixed to the dataset available at the initial compile time.
Lenat developed heuristic discovery algorithms for optimizing LISP code
[Len83]. Lenat's work was limited to source-to-source
transforms on LISP programs to improve performance. As noted above (See
Section ), source-level transforms do not get directly at
optimizing the production of efficient executables. Instead, we seek to
optimize the program by working directly with the compiler transforms used
to produce efficient executables. Lenant's optimization was based on
assertions about LISP level operators and was completely separate from the
optimization performed by the compiler whereas we see the integration as a
key component for achieving high performance. Lenant used little, if any,
feedback from execution.
The compilers goal is to transform a program to decrease execution latency. The compiler has a large set of primitive transforms for restructuring code. Contemporary experience shows that combinations of even simple transforms can have complimentary effects resulting in significant gains. The task for the compiler, then, is to sort through the huge space of potential transforms and transform compositions minimize run-time. As noted, this task is difficult, if not impossible, for the compiler to perform well without knowledge of common usage patterns. In particular, the compiler lacks information about:
With this dynamic information, the compiler can restructure code to decrease execution latency. Trace scheduling can be used to decrease the path lengths along commonly utilized paths. As run-time invariants are discovered, code can be restructured to optimize for the expected run-time behavior. Aggressive inlining and specialization can be applied exploiting expected run-time properties. Further run-time feedback can demonstrate the effectiveness of each optimization.
From run-time feedback, the compiler discovers lacking information, as well as, its own ability to predict each piece of information which may be run-time dependent. The compiler can then use efficient, offline techniques to determine the best code sequence for low execution latency based on what it expects to happen at run time and the known certainty of its expectations.
It will, of course, be important to abstract away the compiler transforms from the user or programmer and deal with incremental code changes. The compiler will represent the program at a fine-grained level including all dependency information ( e.g. who uses, who calls). The actual compiled code will often inline and collapse or specialize across abstraction boundaries in the original high-level program. When the programmer makes changes, the compiler can use the program dependencies to determine which portions of compiled code are affected and must be reverted and reoptimized. The compiler's database for the program will allow it to recover the original description for all affected portions of the program. For quick code changes, it may revert to a lightly optimized version of the code to allow the programmer to quickly make use of the changes made. Over time, the new code will be further collapsed, profiled, and optimized as part of the compiler's normal operation.
End users generally care primarily about application performance on the set of applications they use regularly. This compilation approaches promises to give the user the best possible performance on their applications, based on the way they typically use them, tailored to the particular machines in use. If a user only uses a subset of the functionality in an application, the compiler recognizes the usage pattern and optimizes for the user's pattern of usage. The user does not end up paying for generality and functions which he does not use regularly. The user is no longer at the whim of the programmer and compiler writer in terms of the dataset for which the program is optimized -- instead, the envisioned compilation system adapts the program to the the user's dataset.
Properly done, this compilation system can significantly raise the abstraction level at which compiler developers interact with developing compilers. The tasks of determining the situations in which transforms are beneficial can be passed off entirely to the compiler. Compiler writers can submit potential transforms and the compiler system automates the task of evaluating the relevant benefit of each transform and how the transforms interact with each other. The compiler can summarize which transforms it finds beneficial in which settings, providing feedback on the utility of each transform automatically. The compiler, in effect, becomes the ultimate peer-review panel for proposed transforms. If a transform helps discover a lower execution time for codes, the compiler uses it and can indicate where and when it is beneficial. If a transform seldom helps discover better run time, the compiler will generally reject the transform. Compiler developers are freed to concentrate on what transforms might be worthwhile to perform and the compiler system takes over the task of evaluating when the transform is beneficial, how beneficial the transform is, and how the transform is best composed with other known transforms.
With this compiler technology in place, portability does not come at the expense of performance. Since compiler uses run-time feedback to tune the program to the target machine, the program can evolve to take best advantage of the target machine. Obtaining good performance on an architecture different from the one on which a program was initially developed, is simply a matter of running the program for some time on the new architecture. The task of discovering the transforms which do and do not work well on the new architecture is subsumed by the compiler.
Contemporary machines use the Instruction Set Architecture (ISA) abstraction to maintain binary compatibility. However, they do so at the cost of performance. Within an ISA family, the members often have widely varying costs for operations and memory latencies. Further, the differences in cache-sizes, memory organization, and virtual-memory systems make run-time behavior different. A program optimized for maximum efficiency on one member of the ISA compatible family will, almost certainly, not be optimal for other members with different latencies and costs. A smart compiler allows the program execution to adapt to the latencies seen in the actual system allowing maximum efficiency on the actual machine in use, not some pedagogical machine with different latencies.
Using collapsing and run-time feedback, the smart compiler can specialize system emulations for near-native performance. In an emulated system, one program serves as an interpreter to provide the view of the original system. Programs which ran on the original system now act like data for the emulation program. The smart compiler can produce very efficient version of the original program running on new hosts systems. First, it can collapse the abstraction between the original program and interpreter and optimize across boundaries which would exist if the two where compiled separately. Secondly, the orginal program is a particular dataset and the smart compiler can optimize the emulation to perform well on that particular dataset. Finally, the benefits of run-time feedback will also extend to the data running on top of the original program, such that it, too, can be specialized for the datasets in use. The smart compiler will allow us to aggressively specialize the combination of the original program and the emulation, allowing us to transport old programs to new hardware systems and achieve good performance on the new hardware with minimal effort.
We also see this kind of compiler technology playing a critical role in the intelligent utilization of distributed computing resources. By nature, a distributed environment is continually changing. Processors, nodes, and interconnect change dynamically due to failures, repairs, and installations. Resources fluctuate for similar reasons, as well as, the usage patterns of other consumers in the system. A smart compiler can direct a program to adapt to the current environment. The compiler can make tradeoffs between local computation and remote computation based on observed communications costs.
In the One Computer model (See (tn93)), the distributed ensemble of computer systems are the One Computer available to the user. The compiler will take this view and optimize for maximum performance on the physical hardware which is available to the user at any given point in time. The smart compiler can experiment with data and execution placement to achieve the lowest execution latency for the user's programs.
Debugging user programs should not be any worse than debugging programs with conventional compilers. The execution of highly optimized programs will bear little resemblance to the original high-level program. As with conventional compiler, the user can debug his logic using a limited set of transforms that preserve sufficient structure from the original program to make error localization easy. As long as the compiler transforms all preserve the correctness of the debugged program, the highly optimized program will be as correct as the debugged program.
This raises the issue of the correctness of the transforms used by the compiler. While the compiler system can certainly verify the relative merit of each transform with respect to run-time performance, in general, it cannot be expected to verify that each transform preserves program correctness. This factor can make debugging difficult when experimenting with compiler transforms.
While we cannot expect the compiler system to discover invalid transforms for us, we can conceive of the system checking the effects of various transforms under the high-level direction of a human. The system can easily automate the tasks of running programs under various conditions ( e.g. transform sets), as well as, the tedious tasks of checking the discrepancies between program runs. The human can then suggest experiments to try to identify the source of errors. The task of determining what is correct will continue to reside with the human programmer, but the task of identifying which transforms generate results which the human identifies as incorrect can be performed by the system.
The problem of generating highly-efficient code is well defined. The search space makes it intractable to use brute-force, exhaustive search techniques to find the optimal solution. The problem is, thus, well suited for application of artificial intelligence techniques. Immediately, we see many opportunities for application of key AI technologies:
On the flip-side the smart compiler is an enabling technology for AI system development. By agressively collapsing abstract code and automatically optimizing high-performance executables, the smart compiler allows us to ``Abstract Up'' (See (tn93)) without worrying about losing performance in the process. This upward abstraction, in turn, allows us to build and reason about larger AI systems.
In the Liquid compilation scheme and architecture [Kni90], programs with side-effects are automatically scheduled for parallel execution using database consistency and dynamic dataflow scheduling techniques. The run-time architecture guarantees correct execution in the presence of side-effects and aliasing. Nonetheless, compiling a program to run efficiently in the liquid schema requires information that cannot be known at compile time. Dynamic dependencies are not known until run-time, making it difficult for a static compiler to schedule the code most effectively without run-time feedback. Just as run-time feedback on branching probabilities allows trace-scheduling compilers to optimize code around the most likely execution path, run-time feedback on dynamicly occurring side-effected, dependencies will allow a smart liquid compiler to optimize code around the most likely dynamic dependency relationships. With run-time feedback, the compiler can resize basic transaction blocks for more efficient execution. Run-time feedback can aid both static and dynamic prioritization and scheduling of transaction blocks to minimize execution latency.
An adaptive, smart compiler can also help applications achieve maximum performance on the non-faulty portions of a large computer. With a sufficiently large computer, it is unreasonable to expect that all the processors, interconnect, and memory in the system will be functioning at any given point in time. Instead, we wish to make most efficient use of the resources which are functional and available at any point in time. In this scenario, the actual resources available for computation are not known until run-time, and may vary during program execution. Since resources vary dynamicly, static scheduling is generally inappropriate. The smart compiler can use run-time feedback about the resources available and the current system performance to retune programs for minimal execution latency on the available hardware.
The compiler system can further provide feedback on the utility of architectural features. With the ability to adapt to varying architectures, the compiler system eases the objective evaluation of the merits of architectures and architectural features. As with compiler transforms, the compiler can summarize the frequency and use of various architectural mechanisms. The compiler can also summarize the critical paths through optimized codes on a machine, identifying the limitations to further latency reductions. This information can be used to identify weaknesses in contemporary architectures and to drive architectural development to further reduce execution latency.
One development in computer architecture which we see as significant is the incorporation of run-time programmable logic arrays in a tightly-coupled fashion with high-speed, scalar processing engines. We see Dynamically Programmable Gate Arrays (DPGA), a descendent of SIMD processing arrays and modern FPGAs which combine the features of both (tn95), playing a fundamental role in future commodity processors in the much the same way that FPUs became an integral part of commodity processors during the past decade. With the advent of these tightly-coupled logic arrays, it becomes possible to reconfigure the processor logic and function to adapt to the computational requirements. In the context of a smart compiler, tightly-coupled Processor/DPGA combinations (see (tn100)) make it possible to not only adapt the executable code to the machine and usage pattern, but also to adapt the machine hardware configuration to the task at hand. The ability to configure custom logic in the processor to speed computation opens up a huge, and largely unexplored, space of potential optimization. A smart compiler can play a key role in intelligently selecting DPGA configurations which speed program execution.
We may encounter a number of social impediments to general acceptance to the smart compiler scheme: