Toward 21st Century Computing:
Transit Perspective
Andre DeHon
Ian Eslick Thomas Knight, Jr.
Original Issue: September, 1993
Last Updated: Tue Mar 8 15:36:23 EST 1994

This document is not about what 21st century computing will be like if we take a hands-off approach and let things develop as they will. Instead, this document begins to describe a vision of what 21st century computing can, and perhaps should, be if we push computing in the right directions as we enter the 21st century.
This vision is currently evolving -- and will, no doubt, continue to evolve. We hope this document will help catalyze thought and discussion in this area. Please, feel free to provide feedback to help us tune the vision and ideas to better represent desirable and attainable computing paradigms for the Twenty-First Century.
As computing progresses into the 21st century, we seek better performance and lower cost as we always have, but we also seek better integration of computing systems with each other, with their users, and with organizations and society at large. Some key concepts which we can embrace to help us achieve these goals and to rise above the computing paradigms we have embraced in the late 20th century are:
The Enterprise Computer from Star Trek: The Next Generation can serve as a decent starting point for modeling computer systems of the future. We can be quite sure that the ``computer'' on the Enterprise is a distributed entity. While never explicitly stated, we can infer the distributed nature from reliability issues alone. Similarly the distribution is necessary when, for instance, the saucer section separates from the main unit. Nonetheless, the distributed computer appears to each user as a single, monolithic computer which runs the ship, maintains data, and interacts with each member of the crew.
One of the key issues here is transparency. There is no reason the users of the system need to see the artificial distinctions between individual computers. When a user wants to obtain data, he should not have to be aware of which machine stores the data. Nor should the user have to pick the ``computer'' where his program runs. The user should simply see various entry points to the One Computer. Perhaps, these entry points are distinguishable by varying input/output devices and bandwidth to the One Computer, but the underlying computer should look the same from all entry points.
Of course, reliability will be a key issue. Distribution of resources provides the potential to tolerate faults in the system. However, many contemporary systems demonstrate all too clearly that distribution without proper fault management is not enough. Many current distributed systems have the property that failure of one resource is sufficient to render the entire system inoperable -- making the ``distributed system'' less reliable than the individual computers from which it is composed. The One Computer should always be up and operational. Some entry point may be down, individual services may be down, and data may become temporarily inaccessible, but the One Computer should be in continual operation.
Due to both the reliability issue and the distributed nature in which the
One Computer is managed, dynamic reconfiguration will be a must.
``You'' as a site or individual will no longer have control over the One
System. Transparently and robustly adapting to an ever changing computer
configuration will be necessary. The One System will need to be designed
to manage this adaptation automatically. Key technologies will be
dynamic fault tolerance to handle changes and failures and adaptive
software. Some aspects of software adaptation are developed further in
Section and (tn87).
The One Computer will be composed of ``Personal Computers'', ``Workstations'', small and large parallel computers, and special purpose machines all connected via a host of network technologies of varying bandwidths and latencies. The One System should deal with this continuum of computation and communications resources in a uniform manner. The users see One Computer, but internally, the One System sees varying performance and bandwidth. The One System can optimize for best performance based on the user's entry-point, access, and data sources. The One System will make tradeoffs between local computation and distribution based on the available resources including bandwidth and computing power. The One System will deal uniformly with the continuum of computational systems from tightly-coupled multiprocessors through distributed systems coupled by long-haul networks. Processing elements will be separated by widely varying bandwidth and latency. The One System should reason about this continuum and optimize the machine usage pattern, communication paradigms, and computational distribution, accordingly.
e.g. Consider asking the One System to run a large spice job. If the network is lightly loaded, and all the links are up, between your entry point ( e.g. your workstation) and a nearby Cray supercomputer, it may ship the job off to the Cray, run the simulation, and ship the results back to your display. But, if the network is congested or flaky, you may get faster results to run the job locally, perhaps on a bigger workstation on a more local subnet. The One System should transparently make these tradeoffs.
There will be some new concerns in the One Computer, One System model. Some of the first new issues to come to mind arise in the area of security and access restriction. Governments, companies, universities, and research groups are accustomed to ``owning'' computers. The artifact of separate systems makes it easy for them to restrict the use of their computer resources and their data to individual groups of people. When the system and machine distinctions begin to go away, alternative mechanisms for restricting the use of machine cycles and access to data must be developed.
In the computational domain, we have been compiling programs from
various ``high-level languages'' to machine executables for decades.
Nonetheless, we would argue the current state-of-the-art machine
translation does only slightly better than interpreting our ``high-level''
constructs when compared to the space available for compilation and
optimization. There remains considerable performance to extract by more
aggressively collapsing our programs at compile time
(Section ) and by using feedback from dynamic
execution to direct compilation (Section
). The realm
of distributed and parallel computing, in particular, stands to benefit
considerably from these more aggressive compilation techniques.
Abstraction is a way of describing and modeling the computation which should take place. It need not be a literal script for the primitive operations which the computer will perform. Abstraction allows us to hide details where the details are unnecessary or obscure function. Abstraction allows us to decompose the problem into smaller components which are easier to understand and reason about. The machine, however, has no good reason to perform the same operations which are literally described by our abstract description. The machine only needs to behave observably, end-to-end, as if it had performed the sequence of instructions abstractly described.
Despite decades of compiler research, we still have plenty of room to collapse our abstractions down and compile much more efficient executable code. Too often, people are still ``implementing their abstractions''. Every time we throw up a barrier, across which we do not allow the compiler to optimize, we lose considerable performance. The more we can provide to the compiler to collapse and schedule at once, the higher the performance we can extract. This is especially true when compiling for today's high-throughput, pipelined, superscalar, VLIW, and parallel computers.
e.g. Consider procedure calls. With the notable exception of leaf-procedure inlining, it remains the case that a procedure call in our high-level program translates directly into a ``procedure call'' at run time, complete with all the stack overhead necessary to implement the ``procedure'' abstraction. This means, every time we introduce a procedure boundary in our ``high-level program'' for the purpose of abstraction, we pay for it at run-time when we literally interpret the procedure abstraction. This problem is exasperated by the fact that most compilers do little in the way of cross-procedure optimizations or procedure specialization.
The procedure call issue highlights the fact that there is room in compiler construction to be more aggressive about reorganizing code to run more efficiently on the available hardware. However, a bigger portion of the problem lies in what we do not feed to the compiler. Today, when the compiler encounters library routines, system routines, and packaged systems ( e.g. windowing systems), it does not get the code and cannot optimize across these boundaries. Further, since it is often given no information about said routines, the compiler must make worst-case assumptions.
System routines in ``Modern Operating Systems'' are some of the worst offenders. To maintain an abstraction of ``a separate space of data secure from user programs'', these ``Modern Operating Systems'' literally implement this abstraction at considerable performance costs to the end applications (See (tn83) [ALBL91]).
Consequently, in today's systems, when people show layered systems on top of some hardware platform, your application pays overhead at run time traversing the hierarchy of layered software. There are no good technical reasons to perform this run-time traversal, and there is considerable performance to be gained by removing it.
Rather than the traditional layered view, we need to model our system
more like the one shown in Figure .
Abstractly, the system can be composed in a manner very similar
to the traditional layered view. However, all the layering is completely
collapsed out by the compiler. At run-time we simply execute the
instructions necessary to get the same answers which the abstract layering
describe. Note, also, that we need execute only those portions of the code
which cannot be evaluated or collapsed at compile time due to data
dependence. The application binary is given direct access to the machine
hardware without interposing an ``Operating System'' layer to hide the
machine performance from the application. As we will see shortly
(Section
) the compiler is an integral part of the
system and its job does not end when the application program starts
running.
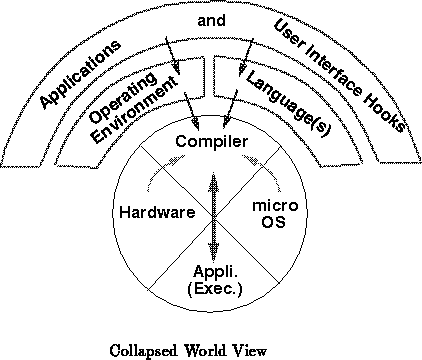
The ``RISC'' effort has taken a small step in the right direction. One key idea that can be extracted from the RISC effort is that by collapsing one level of abstraction in the execution hierarchy ( i.e. microcode) and exposing the lowest-level instructions to the compiler for scheduling and optimization, the processor's basic hardware resources can be used more efficiently. The RISC effort, however, only collapsed one layer of the abstraction hierarchy. We still have room to gain by collapsing the rest of the layers in the hierarchy.
On the positive side, we can note that researches working on partial evaluation ( e.g. [Ber89]) are developing technologies for aggressively collapsing abstractions at compile time. Work in this area underscores the potential benefits of further collapsing. The current work on partial evaluation, however, requires the user to explicitly provide much of the data necessary to allow abstraction collapsing to occur. Partial evaluation alone has limited ability to cope with data dependent control flow
By providing more information to the compiler, however, we can do an even better job at producing highly efficient code. In particular, we can make use of run-time feedback in a Smart Compiler to produce code which is more efficient than staticly compiled code. By giving the compiler access to run-time execution information, the compiler can discover information from run-time which is impossible to determine statically. Such information would include:
In this model, instead of compiling an executable and then leaving it alone, the compiler's work is never done. Profiling information is collected as an integral part of execution. The compiler continually evaluates this information to tune the program. The compiler is empowered to mutate the executable to experiment with new transforms and discover the best way to run the program on the available hardware. By monitoring expectations, the compiler can note changes in the usage pattern of program and adapt the executable accordingly.
The compiler runs all the time in ``spare'' machine cycles and maintains a database of information about each application. By ``spare'' machine cycles, we mean cycles which cannot serve to run the application. This can be idle time on a ``workstation'', idle processor cycles on a multiprocessor, or combinations thereof. In some cases the compiler may chose to rerun applications from its database of previous runs to experiment with code transforms. While the user is thinking or when the users are home at night and have not left the machine with tasks to run, the compiler can rerun the programs of the previous day and take the time to learn how it could have run the programs faster. The compiler can even use its execution history to determine which programs and portions of programs are used more frequently and hence should get a higher priority for optimization during the available spare cycles.
We can view this smart compiler as a
High-throughputLow-execution-latency Transmogrifier. It can
automate the process of making throughput versus latency tradeoffs in
scheduling. Additionally, it uses spare compute cycles (extra throughput)
to reduce execution latency on future program runs.
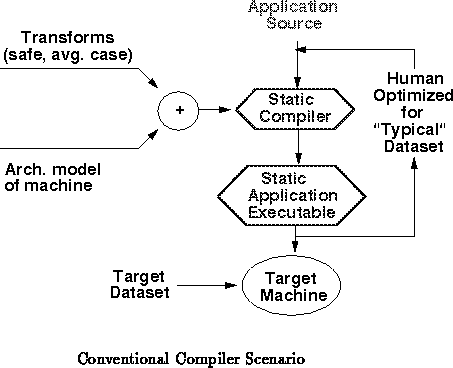
In the current compilation scenario (See
Figure ), the application developer compiles his
program with a compiler which was optimized to do well on typical codes.
This compiler was also optimized to target machine code to some
prototypical instances of the architecture on which the code will
eventually be run. Several compromises are made in generating this static
compiler. First, the compiler uses a static set of transforms which have
been determined to generally improve typical programs. Optimizations which
may improve some programs may have been omitted for lack of distinguishing
criteria about which programs they will improve. Other optimizations which
may pessimize some programs may have been kept because they improve most
programs. The compiler is static and will continue to behave this way
until replaced with a new version. Secondly, this static compiler does not
know the actual performance of operations on the target machine. Rather,
to limit the number of machines and configurations for which different
compilers are necessary, it simply targets an architecture abstraction.
The compiled executable, thus, cannot be fully optimized to most
efficiently use the machines upon which it finally runs. Further, the
application delivered is also static. The compiler cannot specialize it to
perform well on any particular dataset or usage pattern. At best, the
application developer will optimize the program for some dataset or usage
pattern which he believes is typical. To do this, he must change the
source program and use his understanding of the application, dataset,
compiler, and architecture to try to make improvements in the program.
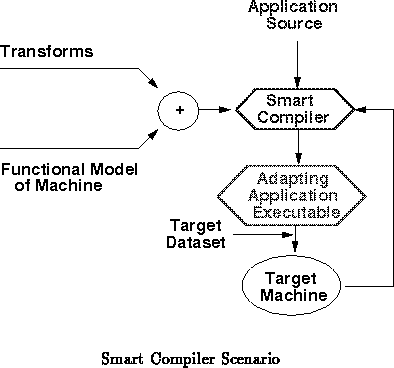
With the smart compiler, these three cases where typical
case assumptions were made can go away (See
Figure ). The end user can get a program
optimized for his dataset and usage pattern and optimized for his machine.
The compiler is free to use a wider set of transforms and can make
intelligent decisions about when to use which transforms. The
specialization process for the user's dataset is handled automatically by
the compiler without modification to the original source code. No one has
to identify a typical dataset to the compiler because it can discover
the actual usage patterns from run-time. The end result is higher
performance for an end-user's application on the user's machine and the
user's dataset.
Properly done, this can mean the death of architecture as a distinguishing feature of hardware. With a basic model of the functional capabilities of any machine, the smart compiler can retarget executables to the new machine. Run-Time feedback allows the compiler to learn efficient transforms for the new machine. The smart compiler allows us to collapse the hardware architecture abstraction, allowing hardware designers the freedom to build the most efficient machine without concern about backward compatibility to an architecture specification.
The smart compiler also lifts the role of the compiler writer. In the current compiler model, compiler developers will conjecture transforms which may speed up execution. The compiler writer then implements them and experiments with how the transform should be composed with other optimizations. The compiler writer then evaluates the transform in an ad hoc way by observing its effect over some benchmark suite. The smart compiler will take over the tedious portions of this work. The compiler writer need only describe the transform to the compiler. The smart compiler then discovers how to best use the transform and compose it with other known transforms to reduce execution latency. After using the transform for a while, the compiler can also summarize the utility of each transform. The compiler becomes the ultimate ``peer review'' for each transform. If a transform is useful, the transform gets used frequently. Transforms which only improve some specific kinds of applications can be retained because the compiler can use feedback from execution to determine the cases where they are actually useful.
Further development on the prospects for a smart compiler can be found in (tn87).
Our current notion of ``high-level'' programming languages is rather low. In the past 20 years, we have not made any notable progress in the level of abstraction with which we can efficiently interact with our computers. The languages of the day are mostly C, LISP, and Fortan, languages developed during the 1950's and 1960's. These languages have mutated some through the years, but generally not in fundamental ways which really raise the level of our machine interaction.
There have been some attempts to abstract upward ( e.g. C++, CLOS). While these attempts have offered some richer data types and some opportunities for abstraction, they have fallen short in a number of significant ways. Consequently, they have not been successful in leading a trend to upward abstraction. One failing these attempts have in common is that they did not adequately hide the lower levels of the abstraction. In their attempt to abstract upward, they left in all of the artifacts and overspecification inherent in the older languages. Consequently, it remains necessary for the programmer to reason about all the underlying complexity of original, lower-level, base language in order to write and understand programs. These attempts at upward abstraction have failed because of poor abstraction -- they left too much of the low-level languages on top of which they were implemented visible. They did not make it any easier for programmers to reason about programs, and they did not make the higher levels of abstraction sufficiently attractive to programmers.
This state of affairs is bad and must be improved. As a consequence of the low abstraction level currently provided, ``programming'' of computers remains a task accessible to only a small, elite class. Even within that elite, productivity is low due to the primitiveness of the interface and the tools. Too much must be overspecified in current languages. This forces the programmer to exert more effort writing suboptimal, overpsecified code that will hinder the compiler from using machine resources most efficiently. We need to abstract up to address these problems. Specifically, uward abstraction is needed to improve:
There are two major reasons why people have resisted upward abstraction:
We can best understand the issue of the tie to performance by looking at why many people prefer C and Fortran to LISP. In C or Fortran, the programmer has traditionally been very close to the actual machine operations. For the most part, there has been a fairly direct mapping between the instructions in the language and the instructions which will be executed at run-time. The programmer feels he has an understanding of the performance of his program and he can control it. The common belief is that LISP is slow and expensive in comparison. The reality is not so much that LISP is generally slow and expensive, but that some features and feature interactions make some operations much more costly than they might look. The real problem is that it requires a fairly deep understanding of the function of the LISP execution model to appreciate the costs of any operation -- an understanding which is beyond what most programmers do know or should have to know. This lack of predictability has frustrated programmers and led them to simply believe that LISP, as a whole, is slow.
Now, it is worthwhile to point out that in today's machines and operating systems even the C or Fortran programmer is typically out of touch with actual performance. The costs of most operations is really less transparent than the programmer might think. The programmer does not know the costs of operating-system and library routines. Many programmers use these routines oblivious of their costs. Others refuse to make use of these routines, essentially rewriting equivalent code, because they do not know their costs. Further, modern memory system design includes caches and virtual memory which make the costs of even simple memory references difficult, if not impossible, to predict. When we consider aggressive compilers, superscalar machines with out-of-order execution, and parallel computers with speculation, the costs of each operation even in C and Fortran are far from transparent and are not easily modelled.
The smart compiler provides the solution to this dilemma in two ways. First, since it takes over the job of optimization, much less of the burden for understanding the costs of operations falls on the programmer. However, there will be programmers who want to make sure they are not losing performance through the abstractions. The programmer will want to assure that the compiler is doing a good job. Compiler writers will want to be sure that the compiler is performing adequately and identify areas where further work is required. To address these problems, the compiler can provide feedback to the programmer, at the level of high-level language instructions, on the costs of each operation. The smart compiler will be collecting and maintaining this information already, so this only requires the additional ability to extract and present the information to the programmer.
n.b. In many ways, this situation is analogous to the acceptance of hardware synthesis from high-level languages. Many hardware designers were reluctant to embrace high-level description and synthesis for fear that they would lose performance. Most have now come to trust synthesis. Their trust was gained by performing synthesis and evaluating the results. After seeing enough examples where the results were as good or better than they could have done by hand, they fully accepted hardware synthesis.
The dearth of successful efforts to significantly raise the abstraction level for machine interaction, leaves us with numerous areas where progress can and should be made. Initially, we can raise the abstraction in the programming languages we employ and in the machine operating environment. As we succeed at raising the abstraction level, the distinction between languages and operating environment will blur.
High-performance computing elements have begun to experience the effects of commodity marketing. While the equipment is expensive, CMOS, VLSI ICs are being produced and sold in sufficiently large quantities to bring the piece cost down to very economical levels. The majority of processing costs can be amortized across designs produced in the same basic IC technology. Nonetheless, the biggest effect of commodity IC production and sales comes into play when the volume of production and sales for a single IC design is sufficient to make the per piece amortized cost of the design, development, testing, and NRE trivial. Today, we see this level of commoditization reaching its heights in the memory ( e.g. DRAMs, SRAMs, EPROMs, Video RAMs) and the processor ( e.g. embedded processors, RISC/workstation microprocessors, DSPs, personal computer microprocessors) arena. These components are being produced in sufficiently large quantities that the costs of investment in equipment and design are completely amortized to negligible per piece costs. Consequently, vendors can afford to sell these components at commodity prices while still making healthy profits.
As high-performance ICs enter the mainstream as commodity items, there is increasing incentive to ride the commodity wave and build systems out of commodity components rather than investing in specialized components. Even if the commodity ICs do not perform optimally for a particular situation, the cost and availability benefits of commoditization makes it difficult to consider customized solutions. Consequently, if we wish to build cost-effective systems, we are generally best served to leverage commodity technologies.
Long-haul networking is emerging as the importance of distributed systems increases. It is beginning to be the case that a single computer in isolation is far less valuable than one which can interoperate with other computers, systems, and databases. Interconnectivity is becoming an essential part of computing and consequently, networking hardware is becoming an integral part of all systems. This integration of network hardware into base systems will propel networking ICs into the commodity realm.
Gate arrays have emerged as cost-effective glue logic to tie together high-performance systems built from commodity components and allow for product differentiation. Nonetheless, since each gate-array design requires its own NRE and design, individual gate arrays seldom reach the high-volume, commodity IC stage. Instead, field-programmable gate arrays are emerging into the commodity role. These components perform the same function connecting systems together and differentiating products. At the same time, they allow increased flexibility for design and repair with lower lead times and NRE risks. These field programmable ICs are already starting to proliferate and will continue to be an important commodity building block for cost-effective systems.
While the set of building blocks already in or entering commodity production is large and allows the construction of a wide variety of high-performance systems, we see two strategic areas where further basic development and commoditization is required.
If we hope to build high-performance, parallel systems from commodity building blocks, it is critical that low-latency, short-haul, networking components become part of the commodity portfolio. The performance of our parallel systems is critically dependent on the speed with which the processing elements and memories can share data. The latencies associated with long-haul networking technologies are too large to serve adequately to providing interconnection in general-purpose, high-performance, parallel systems. Low-latency routing elements should be a part of our 21st century commodity building block set. Further, for highest performance, 21st century commodity processing elements should integrate short-haul networking support.
Dynamically Programmable Gate Arrays (DPGAs) combine the abilities of traditional FPGAs and SIMD arrays to realize a hybrid structure more powerful than either. In particular, DPGAs allow each array element to perform a different operation like DPGAs, but they also allow the elements to perform a different operation from clock cycle to clock cycle like SIMD arrays. This ability allows DPGAs to subsume the functions of both FPGAs and SIMD arrays. Thinking of DPGAs like FPGAs, they can effectively switch among a small set of programmed configurations on a cycle-by-cycle basis. Thinking of DPGAs as SIMD arrays, they can perform different operations at each array site allowing increased flexibility. (tn95) introduces DPGAs and describes their potential application and benefits in more detail.
Combining these commodity building blocks, the 21st century commodity microprocessor will be very powerful and versatile. To review, a 21st century microprocessor will be composed of:
By including programmable array logic in a tightly-coupled configuration
with the processing elements, we enable the compiler to compile all the way
down to the gate level. Here, we see a merger of compiler technology and
synthesis technology. We empower the compiler to configure functional
logic structures which were not native to the original microprocessor
design. Thus, application specific acceleration logic can be employed to
achieve higher computational performance. Ultimately, we see the smart
compiler (Section ) determining how to best configure
the DPGA structure for improved performance on each application.
One further variation we can make on this theme is to allow configuration of the datapaths between the hardwired ALUs, FPUs, register-files, and memory. This scenario is much akin to using core-logic cells in a traditional gate-array. The basic ``processor'' has some fixed macro cells, memory, and array logic. The datapaths between all the cells as well as the array logic are fully configurable at run-time. The compiler is then empowered to configure the datapaths optimally on an application by application basis. The compiler can even go so far as to reconfigure the datapaths between varying regions of the same application. This configuration gives the compiler very fine-grained control over the hardware allowing it to match the hardware configuration to the computational requirements and hence make the most effective use of the hardware elements provided.
Since we will not be able to instantly convert all systems and software over to this 21st century view, we must consider how existing systems are dealt with during the transition.
During the transition, one key will be to mold the existing distributed systems to fit into the One Computer worldview. With an appropriate environment, systems which are part of the One Computer can view existing, distributed systems as part of the One System. This will require the One System operating environment to synthesize the proper view of the external system. The One System can utilize the services and computational resources of the external systems. However, it must take additional care to verify the correct operation of the external system. In particular, the One System must assume that the external system can fail at any point and deal with such failure when it occurs. The One System must be able to adapt around the external systems.
For the adaption of existing software, the smart compiler utilizing collapsing and run-time feedback should make it possible to bring old software into the future at reasonable performance. By describing the environment of the old system executable to the smart compiler it should be possible to meaningfully import old executables to the compiler. The smart compiler can then restructure and reoptimize the old executable for good performance on the new system. Abstraction introduced in describing the old system model will be compiled out when generating the new application executable using aggressive collapsing. Run-Time feedback allows the compiler to further optimize around artifacts of the existing system. Emulators which run DOS/x86 executables on modern, RISC processors provide existence proofs that the emulation is possible. Translators which re-compile DEC/VAX executables for DEC/Alpha systems provide further existence proofs. The addition of collapsing and run-time feedback offer a potential for generating much higher execution performance for the translated or emulated code.
We have described a vision for computing in the 21st century. In many aspects, this is not the system which will emerge if the current industry and research community are left to evolve computing paradigms without direction. The system view presented here can lead to a superior system in many important ways. As a first step, we need to tune this vision and flesh out how to bridge from current computing paradigms into this future.
We can roughly break the major areas for research and development into five key areas: