
Transit Note #34
MBTA: Software Model
Andre DeHon
Original Issue: December 1990
Last Updated: Mon Nov 8 17:13:46 EST 1993

Overview
This note describes the basic software model for programming MBTA. The
goals of this model are:
- To facilitate programming model development and refinement
decoupled from the details of a particular machine
- Aid in the convergence of model-independent parallel mechanisms
- To facilitate parallel hardware-architecture development and
evaluation decoupled from a particular programming model
- To facilitate decoupled development and evaluation of the
components of a hardware architecture
The basic idea and goals described here are not novel. This
model-architecture decoupling is a common vision shared by many
architecture researchers at MIT, including Tom Knight, Bill Dally, Greg
Papadopoulos, and others. MBTA attempts to exemplify this decoupled approach
and utilize it to leverage decoupled architectural evaluation.
Basic Model
Figure  shows the basic structure of this model. Ideally,
the applications programmer can express programs in any of the various
parallel programming models. A language/model specific compiler translates
his program into a Register-Transfer-Level Language appropriate for
expressing parallel computations. The language specific compiler performs
any basic optimizations it can in producing the parallel-RTL translation of
a program. This parallel-RTL is the common language used for communication
among models and hardware architectures. An architecture specific compiler
then compiles the parallel-RTL down to a specific hardware architecture and
optimizes the program for execution on the specific hardware. For each
hardware architecture, emulation support code is used to allow programs to
be executed and evaluated on the MBTA hardware.
shows the basic structure of this model. Ideally,
the applications programmer can express programs in any of the various
parallel programming models. A language/model specific compiler translates
his program into a Register-Transfer-Level Language appropriate for
expressing parallel computations. The language specific compiler performs
any basic optimizations it can in producing the parallel-RTL translation of
a program. This parallel-RTL is the common language used for communication
among models and hardware architectures. An architecture specific compiler
then compiles the parallel-RTL down to a specific hardware architecture and
optimizes the program for execution on the specific hardware. For each
hardware architecture, emulation support code is used to allow programs to
be executed and evaluated on the MBTA hardware.


Programming Models
Ideally, we would like to support all emerging models for expressing
parallel computation. However, given how large and disperse the field
currently is, supporting every model is impractical. To provide the
breadth we intend for studying the requirements of various models, we would
like to support at least one or two programming languages within each major
model. In the remainder of this section, I consider a few potential
candidates to support.
Dataflow
Being at MIT, probably the most accessible dataflow
language to support would be ID [Nik88]. Perhaps, we could start
from some of the Computational Structures Group's intermediate dataflow
graphs and do our translation to a parallel-RTL from those pre-digested
forms. Another popular functional/dataflow language to consider would be
ML.
Concurrent Message Passing
Given the variety of concurrent
message passing programming languages existing today, it is much less clear
what would be best to support in this genre. One interesting mainstream
language to support would be MCC's GNU C++; this would give us access to
the code people have written to run on MCC's ES-KIT computers
[Smi90]. Other languages to consider would be CVA's Concurrent
Aggregates [CD90] [Chi90] or Concurrent SmallTalk
[Hor89].
Shared Memory
There is also quite a range of languages and
models under the rough category of shared memory. We almost certainly want
to support one of the languages extended with futures. The obvious
possibility would be Kranz's Mul-T; perhaps the best strategy would be to
support translation from Alewife's intermediate form WAIF [Maa90]
to our parallel-RTL. Other interesting candidates to support would be
Weihl's transaction oriented model and FX-90 [GJS90].
Sequential Languages
Schemes such as Knight's mostly-functional
programming language paradigm [Kni86] make it reasonable to
support some ordinary sequential languages.
Data Parallelism
Supporting some form of expressing data-level
parallelism is a must. Fortran-9x would be one of the obvious candidates
to support in this genre.
Other
It would also be nice to support Berlin's partial
evaluation paradigm [Ber89] in some form.
Parallel-RTL
Parallel-RTL (PRTL) is intended to serve the same function as a Register
Transfer Language serves for sequential languages. That is, the PRTL will
be a machine-independent description of the computation that is
highly-amenable to direct optimization using current and emerging compiler
technology. The PRTL will serve as the generic low-level expression of the
computation described by the high-level programming languages. The PRTL
may be described in a dataflow graph form broken into basic blocks.
One goal of the PRTL will be to effectively express programs in a model
independent manner and capture the common requirements of all models. The
PRTL will probably change quite dynamically as we begin to support various
models. Hopefully, as we begin to better understand the requirements of
each model, the PRTL will converge to distill the essential underlying
expressiveness necessary to support all models efficiently.
Most modern compilers use some form of RTL internally. Where possible,
we would like to leverage the work put into these compiler by working from
the native RTL. The translation from a compiler's RTL to our PRTL should
be a much simpler matter than generating a complete compiler from scratch.
Architecture Emulation
Machine Compilers
The common PRTL is then compiled to a target machine architecture. This
final compiler attempts to efficiently translate the machine independent
PRTL into machine specific code for a particular hardware architecture.
This compiled code, with appropriate support, can then be run on MBTA to
evaluate the machine architecture in question.
Software Hardware Modules
The hardware architecture under study is emulated by a collection of
software modules. This emulation software runs on each node so that each
MBTA node can effectively pretend to be a node of the hardware architecture
in question.
A typically, a hardware architecture would be described in a modular
manner with a separate module for emulating the actions of each major
portion of the architecture. E.g. a typical node architecture might
be realized with one module emulating a particular processor design,
another implementing the cache controller, and a third embodying the
network interface component (see Figure ). During
each emulation cycle, each module gets its respective time-slice to
emulate the behavior of the compoment it models.
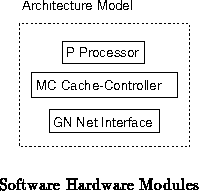
With proper modularity, it should be possible to ``pick-and-chose''
modules to construct an emulated architecture. This will allow architects
to study the interactions and performance of various hardware combinations.
This scheme should be useful for evaluating the
processor-to-cache-controller and controller-to-net interfaces proposed in
[Lei90]. Once these interfaces are settled, it should be
trivial to ``mix-and-match'' processor, controller, and network interface
modules for emulation.
To be effective, each software module should gather appropriate
statistics on the performance and behavior of the hardware unit being
emulated during program execution. These statistics will be critical to
evaluating and comparing architecture combinations and their effectiveness
at executing programs in various programming models. As we get further
experience using MBTA in this manner, we will certainly want to define a
set of standard statistics to be collected by all models.
Environment for Model Inter-operation
As a part of providing multi-model support on a single virtual platform,
it would be most beneficial to allow the models to inter-operate. That is,
it should be possible for programs written under different models to
coexist simultaneously on a machine. Programs should be able to interact
in some controlled way. The interaction might even allow programs to call
upon routines written in different models. Ideally, we would like to
establish an environment and conventions that allow programs and routines
expressed in different models to mutually coexist.
Benefits
Getting a moderately complete system of this form running will require a
non-trivial amount of effort and man-power. It is useful to consider the
benefits we hope to gain by undertaking this task.
Evaluate model-independent Architectures
In order to seriously
evaluate model-independent architectures, we really need a platform that
makes code from all major models accessible to the architecture under
study. Attempting to provide a common middle-ground for expressing the
computations implied by each model is a crucial step towards understanding
the computational requirements in a model independent manner.
Code Leveraging
Supporting a reasonable range of languages and
models should give us access to existing code and benchmarks. Leveraging
these applications and benchmarks should provide a wealth of meaningful
tests for proposed architectures.
Independent work on Architecture Components
This scheme should
facilitate independent work on the various pieces of an architecture. The
structure should provide the support ( e.g. access to meaningful
code, modular hardware support, basic run-time model) to allow
architectural pieces to be developed in a decoupled manner.
Path to Real Machines
The path from studies in this software
model to a real machine should be readily apparent. Everything down to the
parallel-RTL should be reusable on the real machine. With an emulation of
the real machine running on MBTA, it should be possible to do much software
development prior to bringing the real machine completely online.
See Also...
References
- Ber89
-
Andrew A. Berlin.
A Compilation Strategy for Numerical Programs Based on Partial
Evaluation.
AI Technical Report 1144, MIT Artificial Intelligence Laboratory,
545 Technology Square, Cambridge MA 02139, 1989.
- CD90
-
Andrew A. Chien and William J. Dally.
Concurrent Aggregates (CA).
In Symposium on the Principles and Practice of Parallel
Programming. ACM, 1990.
- Chi90
-
Andrew Chien.
Concurrrent Aggregates (CA): An Object-Oriented Language for
Fine-Graned Message-Passing Machines.
AI Technical Report 1248, MIT Artificial Intelligence Laboratory,
545 Technology Square, Cambridge MA 02139, 1990.
- DeH90a
-
Andre DeHon.
Early Processor Ideas.
Transit Note 11, MIT Artificial Intelligence Laboratory, May 1990.
[tn11 HTML link] [tn11 FTP link].
- DeH90b
-
Andre DeHon.
Global Perspective.
Transit Note 5, MIT Artificial Intelligence Laboratory, May 1990.
[tn5 HTML link] [tn5 FTP link].
- DeH90c
-
Andre DeHon.
MBTA: Modular Bootstrapping Transit Architecture.
Transit Note 17, MIT Artificial Intelligence Laboratory, April 1990.
[tn17 HTML link] [tn17 FTP link].
- DeH90d
-
Andre DeHon.
MBTA: Thoughts on Construction.
Transit Note 18, MIT Artificial Intelligence Laboratory, June 1990.
[tn18 HTML link] [tn18 FTP link].
- DeH90e
-
Andre DeHon.
Memory Transactions.
Transit Note 13, MIT Artificial Intelligence Laboratory, May 1990.
[tn13 HTML link] [tn13 FTP link].
- GJS90
-
David K. Gifford, Pierre Jouvelot, and Mark A. Sheldon.
Report on the FX-90 Programming Language.
Technical report, MIT Programming Systems Research Group, 545
Technology Square, Cambridge MA 02139, September 1990.
- Hor89
-
Waldemar Horwat.
Concurrent Smalltalk on the Message-Driven Processor.
Master's thesis, MIT, 545 Technology Square, Cambridge MA 02139,
1989.
- Kni86
-
Thomas F. Knight Jr.
An Architecture for Mostly Functional Languages.
In Conference on LISP and Functional Programming. ACM, 1986.
- Lei90
-
Charles E. Leiserson.
VLSI Technology for Reliable Large-Scale Computing, January 1990.
DARPA Proposal.
- Maa90
-
Gina Maa.
WAIF.
unpublished draft, 1990.
- Nik88
-
Rishiyur S. Nikhil.
ID Version 88.1 Reference Manual.
Computation Structures Group Memo 284, MIT, 545 Technology Square,
Cambridge MA 02139, 1988.
- Smi90
-
Robert J. Smith.
Experimental Systems Kit Performance Characterization and Development
Progress.
MCC Technical Report ACT-ESP-114-90, Microelectronics and Computer
Technology Corporation, Austin, Texas 78759-6509, March 1990.